手元にある写真を、VRデバイスで立体的に表示させたくありませんか?
そこでおすすめなのが Depth Anything V2。このAIを使えば、普通の写真からでも奥行き情報を推定して、自分だけの3D画像 に変換できます。作った立体画像を Quest や Pico などのVRデバイスで再生すれば、写真の中に入り込んだかのような臨場感を体験できます。
もちろん動画も同じ手順で3D化できるので、撮影した2D動画をVRで楽しむことも可能です。Windows環境で手元の写真や動画をサクッと3D化し、VRで没入体験を楽しむ方法を解説します。
Depth Anything V2とは

Depth Anything は、Meta社が開発したAIモデルで、普通のカメラで撮った画像から、物体までの距離(=深度)を予測できる技術です。
これまで奥行きを測るには、ステレオカメラやLiDARなどの特殊なセンサーが必要でしたが、Depth Anything は画像1枚だけで奥行きを推定できる画期的な技術です。
従来の深度推定は、
- ステレオカメラ:左右2台のカメラで撮影し、画像のズレから距離を計算
- LiDAR:光を飛ばして、跳ね返ってくる時間から距離を測定
- ToFセンサーや構造光:赤外線で空間をスキャンして距離を取得
これらは高価で、環境にも左右されやすく、誰でも気軽に使えるものではありません。
Depth Anything V2 は、初代モデルをさらに強化した最新版であり、以下のような点が進化しています。
- より多様な画像に対応:屋外・屋内・人物・風景など、幅広いシーンで高精度な推定が可能
- 学習データの大幅増加:ラベル付き画像150万枚+ラベルなし画像6200万枚以上を活用
- 推論速度の向上:軽量化されたモデルにより、リアルタイム処理も可能に
Depth Anything V2 の公式サイト
Video Depth Anything V2 の GitHub公式ページは以下の通りです。このページにインストール方法やモデルのダウンロードリンクが掲載されています。本記事は、この内容をWindows 11環境で検証したものです。
https://github.com/DepthAnything/Depth-Anything-V2?tab=readme-ov-file
環境構築手順の概要
環境構築に関する予備知識(概要)を簡単に紹介しておきます。詳しくは次の章で解説しています。
Python/CUDAのバージョン
| 必要な環境・ライブラリ | バージョンなど | 備考 |
|---|---|---|
| Python 環境 | Python 3.10.11 | |
| Git 環境 | その時の最新版 | |
| ffmpeg | その時の最新版 | 3D動画に元動画の音声を移したい場合に必要。 |
| Pytorch | ttorch==2.1.0(cu121) | |
| CUDA Toolkit | 12.1 | |
| cuDNN | 8.9.0以上 |
プログラム/モデルのインストール方法
| Step1 Python動作環境の構築 | ①Python 3.8.10の環境準備 ②Gitの環境準備 ③CUDA Toolkit 111のインストール ④cuDNN 8.0.5 |
|---|---|
| Step2 プログラム のインストール | GitHubからVideo Depth Anything をインストール後、各種モジュールを pip コマンドにてインストールします。 |
| Step3 モデルのインストール | GitHubに公開されているページから学習済みモデルファイルをダウンロードし、所定のフォルダにコピーします。 |
インストール手順
Step1.Python動作環境の構築
「【最初の一歩】生成AI向けPython環境構築手順(スクリーンショットで解説)」の記載内容(①②③④)を実行してください。
Python環境構築手順の①~④をインストールしてください。
Step2.Depth Anything V2のインストール
あらかじめ、Depth Anything V2をインストールするための任意のフォルダを作成しておきます。
本記事では、Oドライブ直下にVDAというフォルダを作成したものとして説明します。
Depth Anything V2 は、「【Python】手持ちの2D動画を3D化!VRで楽しむ3D動画の作り方(Video Depth Anything)」の記事で紹介した動画の深度推定の元となる技術であるため、動作環境は全く同じです。
両者の共存を前提に、上記の記事で作成した場所(Oドライブ直下にVDAフォルダを作成)にインストールすることを前提に解説しています。
まず、コマンドプロンプトを開き、インストールしたいフォルダ(今回はOドライブ直下の VDAフォルダ)に移動し、次のコマンドを実行します。
git clone https://github.com/DepthAnything/Depth-Anything-V2
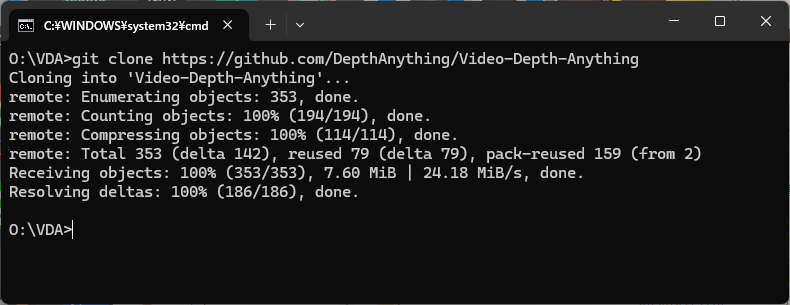
Video Depth Anything の環境を既に構築済みの方は、以上で環境構築は完了です。Step3に進んでください。
それ以外の方は、次のコマンドを実行してください。
cd Depth-Anything-V2
pip install -r requirements.txt
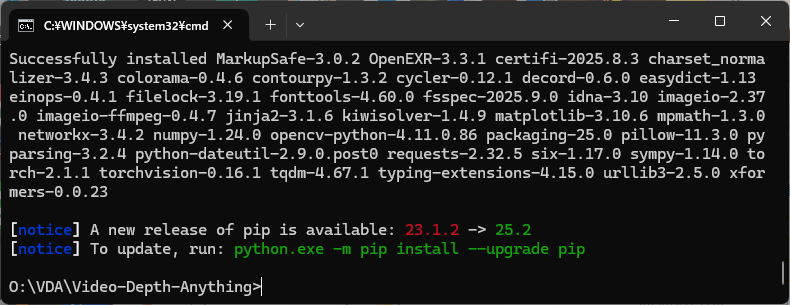
CPUだけで深度推定を行う場合はここで完了です。しかし、CPUだけだとわずか10秒の動画でさえ、数十分程度の処理時間が必要となります。
NVIDIAのGPUをお持ちの方は、下記のコマンドを実行してください。これでGPUが使えるようになります。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install xformers
Step3.モデルのダウンロード&インストール
下記のダウンロードのリンクから、必要なモデルをダウンロードします。
ダウンロードが完了したら、Depth-Anything-v2 をインストールしたフォルダに checkpoints というフォルダを作り、そこにモデルファイルをコピーします。

使い方
コマンドラインによる深度推定
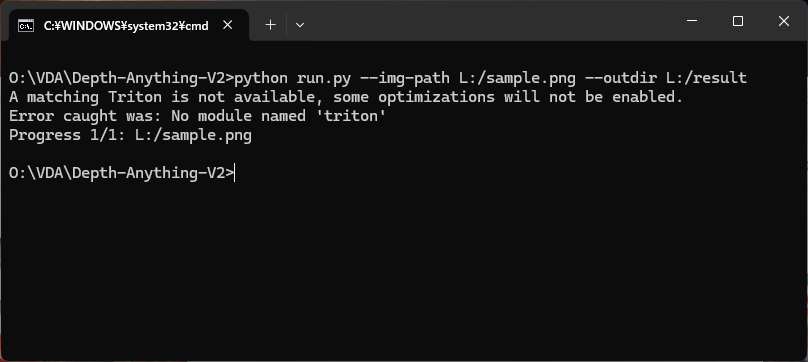
コマンドプロンプトを開き、Depth-Anything-v2 をインストールしたフォルダに移動し、run.pyを実行することで、深度推定が行えます。
この時、--img-path で指定した画像と同じ場所を --outdir で指定してしまうと、元の画像が上書きされるのでご注意ください。
尚、--encoder には 3種類のモデル(vits、vitb 、vitl 詳細は後述)が指定できますが、省略するとvitlが採用されます。
python run.py --img-path 入力画像 --outdir 出力先フォルダ --encoder モデルサイズ --grayscale
--img-path にフォルダを指定すると、そのフォルダに含まれる画像を一括処理してくれます。
下記は、Lドライブ直下の sample.jp の深度推定結果を、Lドライブ直下に出力する例です。
python run.py --img-path L:/sample.jpg --outdir L:/result
深度推定に成功すると、入力に指定した sample.jpg の右に深度推定画像が付加された画像(png形式)が出力されます。
sample.png(入力画像)

sample.png(出力画像)

出力画像をよく見て頂くと、中央に白い境界の帯が入っていることが分かります。この境界線の幅は一定ではなく、入力画像のサイズに応じて幅が広がるため、深度マップを取り出す際に幅の考慮が必要になります。
今後の3D化を考え、この幅を0にしたいと思います。具体的には run.py スクリプトの71行目にある split_region,を削除してください。具体的には以下のように修正します。
# 変更前(71行目)
combined_result = cv2.hconcat([raw_image, split_region, depth])
# 変更後(71行目)
combined_result = cv2.hconcat([raw_image,depth]) 上記の修正を行うことで、 run.py の出力結果から縦の境界の帯を消すことができます。

run.py には次のパラメータが指定できます。
| パラメータ | デフォルト値 | 説明 |
|---|---|---|
| --img-path | なし (必須) | 入力画像のパス。 ・画像ファイルを指定可能 ・ディレクトリを指定すると中の全画像を処理 ・ .txt を指定するとリストファイルから読み込み |
| --input-size | 518 | 推論時に入力画像をリサイズする際のサイズ(正方形にリサイズ)。 |
| --outdir | ./vis_depth | 出力ディレクトリ。深度推定結果(PNG形式)が保存される。 |
| --encoder | vitl | 使用するエンコーダモデル。選択肢:vits, vitb, vitl, vitg。 |
| --pred-only | False | フラグを有効化すると、入力画像との比較をせずに 深度マップだけ 保存する。 |
| --grayscale | False | フラグを有効化すると、カラーマップを使わずに グレースケール深度マップ を出力する。 |
モデルサイズごとの処理速度と深度推定品質の比較
処理速度と深度推定の品質はモデルサイズで決まるので、モデルごとに処理時間と深度マップの品質を調べてみました。処理速度の数値は画像の複雑さによって異なりますので、あくまでも今回の画像における参考値とお考え下さい。
今回のケースでは、BaseモデルとSmallモデルの処理時間の差は12%ほどですが、BaseモデルとLargeモデルの差は42% ほどありました。処理時間の差に比べて品質の差はほとんどないので、BaseモデルかSmall モデルを選択するのが良さそうです。
| モデルサイズ | 512×512 画像の深度推定にかかった時間 |
|---|---|
| small | 0.32秒 |
| base | 0.36秒 |
| large | 0.51秒 |
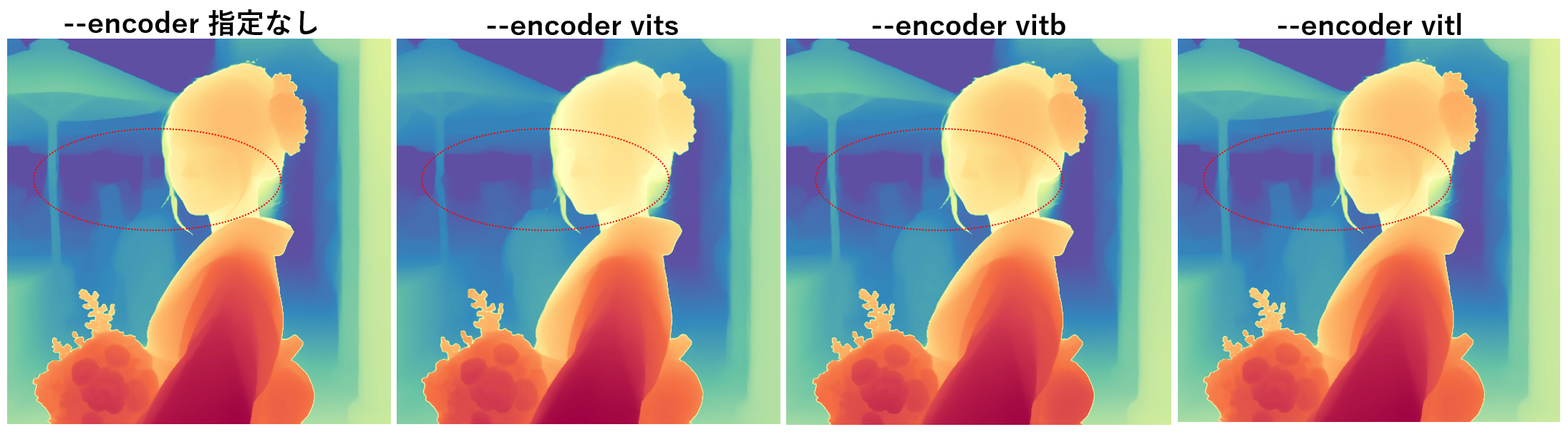
下記は --encoder の違いによる深度マップの差です。画像をクリックすると等倍で表示できます。--encoder指定なしの場合は、vitl が選択されます。
こうして比べてみると、一見差がほとんど感じられませんが、赤い楕円で囲った部分のディテールが微妙に異なっていることが分かります。
Web UI を使った深度推定
嬉しいことに、WebアプリによるUIも利用可能です。
但し、これを使うには事前に下記の2つをインストールしておく必要があります。
pip install gradio
pip install gradio_imageslider
Webアプリの起動には app.py を使います。次のコマンドを実行してください。
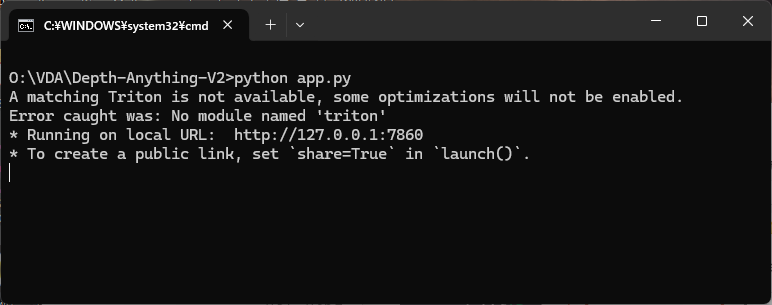
python app.py
起動に成功すると下記の表示になります。表示されているURL(下記例では http://127.0.0.1:7861 )にお使いのブラウザからアクセスしてもらえれば、UIによる深度推定が可能です。
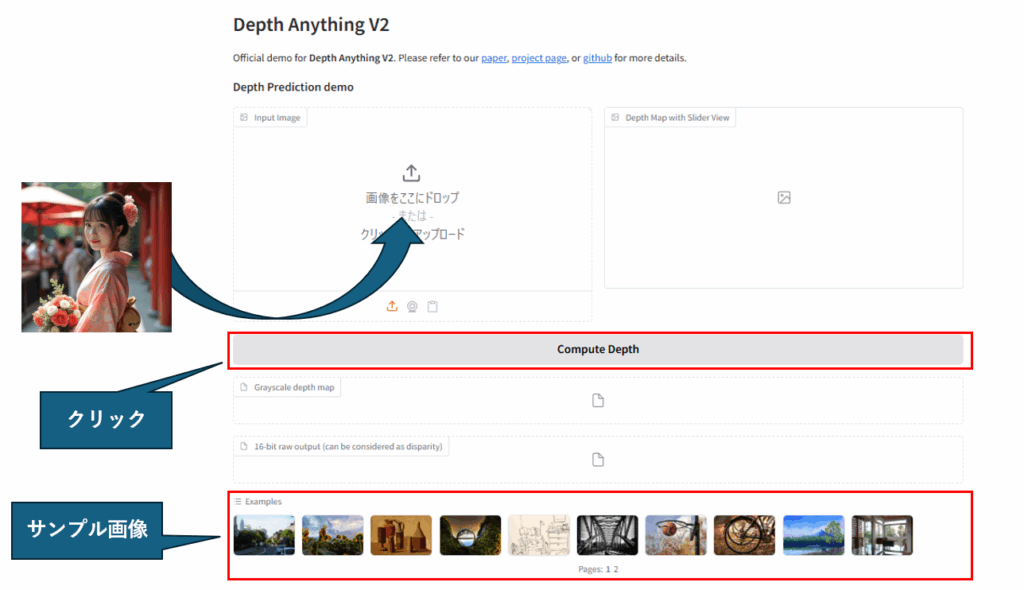
使い方は簡単で、画像をドラッグ&ドロップして、「Compute Depth」ボタンをクリックするだけです。
ただし、ドラッグ&ドロップできるのは単一の画像だけです。
フォルダをドラッグして一括処理することはできません。
深度推定の結果から3D画像を作成するプログラムの紹介

Depth Anything V2 が生成する深度マップ付き画像から、3D画像を生成するプログラム(スクリプト)を作りました。make3dimg.py という名前です。
python make3dimg.py --input_dir 入力フォルダ --output_dir 出力フォルダ
| 引数 | デフォルト | 説明 |
|---|---|---|
| --input_dir | なし(必須) | 元画像が入ったフォルダパス |
| --output_dir | なし(必須) | 深度マップ付き画像の出力先フォルダ |
| --max_shift | 10 | 最大視差ピクセル数。大きいほど立体感が強くなる |
| --half_sbs | False | 指定すると幅半分SBSで出力。指定なしはフル幅SBS (※ --half_sbs True ではなく --half_sbs だけでOK) |
下記のソースコードを make3dimg.py というファイル名で保存してください。
import os
import cv2
import numpy as np
import argparse
# ------------------------------
# VR用SBS画像生成関数
# ------------------------------
def create_vr_image(src_frame, depth_frame, max_shift=10, half_sbs=True, depth_min=0, depth_max=255):
"""
元画像と深度マップから左右視差を持つVR用SBS画像を生成
Parameters
----------
src_frame : np.ndarray
元画像
depth_frame : np.ndarray
深度マップ画像
max_shift : int
最大視差(ピクセル)
half_sbs : bool
Trueなら幅半分SBSで出力
depth_min : int
深度マップの最小値
depth_max : int
深度マップの最大値
Returns
-------
np.ndarray
左右視差付きSBS画像
"""
height, width = src_frame.shape[:2]
depth_gray = cv2.cvtColor(depth_frame, cv2.COLOR_BGR2GRAY).astype(np.float32)
depth_norm = np.clip((depth_gray - depth_min) / (depth_max - depth_min), 0, 1)
shift = depth_norm * max_shift
map_x, map_y = np.meshgrid(np.arange(width), np.arange(height))
map_x = map_x.astype(np.float32)
map_y = map_y.astype(np.float32)
map_x_left = map_x - shift
map_x_right = map_x + shift
left = cv2.remap(src_frame, map_x_left, map_y, interpolation=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REPLICATE)
right = cv2.remap(src_frame, map_x_right, map_y, interpolation=cv2.BORDER_REPLICATE)
if half_sbs:
left_half = cv2.resize(left, (width // 2, height))
right_half = cv2.resize(right, (width // 2, height))
combined = np.hstack((left_half, right_half))
else:
combined = np.hstack((left, right))
return combined
# ------------------------------
# 画像1枚処理
# ------------------------------
def process_single_image(img_path, output_dir, max_shift=10, half_sbs=True):
"""
1枚の画像からVR用3D画像を生成して保存
Parameters
----------
img_path : str
入力画像(左:元画像 / 右:深度マップ)
output_dir : str
出力フォルダ
max_shift : int
最大視差
half_sbs : bool
Trueなら幅半分SBSで出力
"""
img = cv2.imread(img_path)
if img is None:
print(f"読み込み失敗: {img_path}")
return
width = img.shape[1] // 2
src_frame = img[:, :width]
depth_frame = img[:, width:]
vr_img = create_vr_image(src_frame, depth_frame, max_shift=max_shift, half_sbs=half_sbs)
os.makedirs(output_dir, exist_ok=True)
base_name = os.path.splitext(os.path.basename(img_path))[0]
out_path = os.path.join(output_dir, f"{base_name}_3D.png")
cv2.imwrite(out_path, vr_img)
print(f"出力完了: {out_path}")
# ------------------------------
# バッチ処理
# ------------------------------
def batch_process_images(input_dir, output_dir, max_shift=10, half_sbs=True):
"""
フォルダ内の画像をすべて処理して3D画像を生成
Parameters
----------
input_dir : str
入力フォルダ
output_dir : str
出力フォルダ
max_shift : int
最大視差
half_sbs : bool
Trueなら幅半分SBSで出力
"""
os.makedirs(output_dir, exist_ok=True)
files = [f for f in os.listdir(input_dir) if f.lower().endswith((".png", ".jpg", ".jpeg"))]
for file in files:
file_path = os.path.join(input_dir, file)
process_single_image(file_path, output_dir, max_shift=max_shift, half_sbs=half_sbs)
# ------------------------------
# コマンドライン引数
# ------------------------------
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Batch 3D SBS Image Generation")
parser.add_argument("--input_dir", required=True, help="入力画像フォルダ(左:元画像 / 右:深度マップ)")
parser.add_argument("--output_dir", required=True, help="出力先フォルダ")
parser.add_argument("--max_shift", type=int, default=10, help="最大視差(ピクセル)")
parser.add_argument("--half_sbs", action="store_true", help="幅半分SBSで出力")
args = parser.parse_args()
batch_process_images(args.input_dir, args.output_dir, max_shift=args.max_shift, half_sbs=args.half_sbs)
深度推定UIツールの紹介
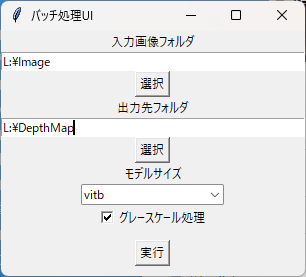
run.py を実行すると深度推定が行えますが、いちいちコマンドラインで指定するのは面倒です。そこで、Python標準のUIライブラリ「Tkinter」で深度推定を行う簡易UIツールを用意しました。
下記ソースコードを ui.py というファイル名で保存してお使いください。
import tkinter as tk
from tkinter import filedialog, ttk
import subprocess
def select_input_folder():
path = filedialog.askdirectory()
input_path_var.set(path)
def select_output_folder():
path = filedialog.askdirectory()
output_path_var.set(path)
def run_batch():
cmd = [
"python", "run.py",
"--img-path", input_path_var.get(),
"--outdir", output_path_var.get(),
"--encoder", encoder_var.get()
]
if grayscale_var.get():
cmd.append("--grayscale")
subprocess.run(cmd)
root = tk.Tk()
root.title("バッチ処理UI")
input_path_var = tk.StringVar()
output_path_var = tk.StringVar()
encoder_var = tk.StringVar(value="vitb")
grayscale_var = tk.BooleanVar()
# 入力フォルダ
tk.Label(root, text="入力画像フォルダ").pack()
tk.Entry(root, textvariable=input_path_var, width=50).pack()
tk.Button(root, text="選択", command=select_input_folder).pack()
# 出力フォルダ
tk.Label(root, text="出力先フォルダ").pack()
tk.Entry(root, textvariable=output_path_var, width=50).pack()
tk.Button(root, text="選択", command=select_output_folder).pack()
# モデルサイズ
tk.Label(root, text="モデルサイズ").pack()
ttk.Combobox(root, textvariable=encoder_var, values=["vits", "vitb", "vitl"]).pack()
# グレースケール
tk.Checkbutton(root, text="グレースケール処理", variable=grayscale_var).pack()
# 実行ボタン
tk.Button(root, text="実行", command=run_batch).pack(pady=10)
root.mainloop()動画の深度推定
Depth Anything V2 には、動画の深度推定を行うスクリプト run_movie.py も用意されています。静止画ベースの深度推定を動画に適用しているだけなので、本格的な動画の深度推定は、Video Depth Anything の利用が適しています。
各フレームを個別に処理し、前後の時間的関係(Temporal Consistency)を考慮しないため、動画としての一貫性は保証されません。また、深度推定後に min/max 正規化を行うため、手前に突然現れる人や車などが最大値となり、背景の深度まで浅く見えるなどの問題が生じます。
run_video.py --video-path 動画ファイルのパス --outdir 出力先フォルダ t --encoder モデルサイズ
下記は、Lドライブ直下に置かれた 72372_1280x720.mov を Lドライブ直下の result フォルダに出力する例です。
モデルは vitb(Baseモデル)を使用しています。--encoder を指定しない場合、Largeモデルが採用されます。
run_video.py --video-path L:\72372_1280x720.mov --outdir l:\result --encoder vitb
Video Depth Anythingで深度推定を行った場合、深度マップは元動画とは別ファイルとして出力されますが、Depth Anything V2では静止画と同様に、左半分に元動画、右半分に深度マップを並べた1つの動画ファイルとして出力されます。

こちらも中央に境界の帯ができてしまうので、これを無くしたいと思います。run_video.py の 50行目の margin_width を 0 にします。
# 変更前(50行目)
margin_width = 50
# 変更後(87行目)
margin_width = 0上記修正後の run_video.py で出力した結果は、「深度推定の結果から3D動画を作成するプログラムの紹介」 で簡単に3D動画に変換できます。
まとめ
今回は、Depth Anything V2 を使って手元の写真や動画を簡単に3D化し、VRデバイスで楽しむ方法を紹介しました。
- 写真や動画から奥行き情報を推定して、自分だけの立体映像を作成
- QuestやPicoなどのVRデバイスで臨場感あふれる没入体験が可能
- Pythonコードを使えば、誰でも手軽に3D化を実行可能
折角のVRデバイス、ただ見るだけで終わらせるのはもったいないです。この記事を参考に、ぜひ自分だけの3Dコンテンツを作り、VRで新しい体験を楽しんでみてください。








コメント