「撮った2D動画、ただ見るだけじゃもったいない!」
そんな時におすすめなのが Video Depth Anything。このAIを使えば、普通の動画や写真からでも、奥行き情報を推定して 自分だけの3D動画 に変換できます。さらに、QuestやPicoなどのVRデバイスで再生すれば、まるで映像の中に入り込んだかのような臨場感を体験可能。
この記事では、Windows環境で簡単に動画を3D化し、VRで楽しむ方法をステップごとに紹介します。
Video Depth Anythingとは

Video Depth Anything は、普通のカメラで撮った「静止画」や「動画」から、物体までの距離=深度(奥行き)情報 を推定できるAIモデルです。
これまでは ステレオカメラ や LiDAR のような特別なセンサーを使わなければ得られなかった情報を、1枚の画像だけで推定できる という点が最大の特徴です。
従来の深度推定は、次のような方法に依存していました。
- ステレオカメラ … 2台のカメラで撮影し、左右の画像のズレ(視差)から距離を計算
- LiDAR … 光を飛ばして、跳ね返ってくるまでの時間から距離を測定
- ToFセンサーや構造光 … 赤外線を利用して物体までの距離をスキャン
これらは高価で環境に左右されやすく、誰でも簡単に使えるものではありません。
一方、Meta社が開発した Depth Anything というモデルは、膨大な画像データを使った学習によって、1枚の画像からでも深度を推定できる汎用AI を実現しました。
静止画なら高精度に奥行きを推定できますが、動画になると課題 が出てきます。
- フレームごとに奥行きの「最大値・最小値」が変わってしまい、映像全体での奥行き感が安定しない
- 手や顔などの動く前景のせいで、背景の奥行きが揺れるように見える
- シーンが切り替わると、深度の基準が急に変わって違和感が出る
そこで登場したのが Video Depth Anything です。このモデルでは以下の工夫により、動画全体を通じて一貫した奥行き推定 を実現しています。
- 過去のフレームの奥行き情報を「指数平均」でなめらかに調整
- 正規化の基準をフレーム間で揃え、映像全体で統一感を維持
- シーンが切り替わっても、急激な深度変化を抑制
Video Depth Anything の公式サイト
Video Depth Anything の GitHub公式ページは以下の通りです。このページにインストール方法やモデルのダウンロードリンクが掲載されています。本記事は、この内容をWindows11 で検証したものになります。
https://github.com/DepthAnything/Video-Depth-Anything
環境構築手順の概要
環境構築に関する予備知識(概要)を簡単に紹介しておきます。詳しくは次の章で解説しています。
Python/CUDAのバージョン
| 必要な環境・ライブラリ | バージョンなど | 備考 |
|---|---|---|
| Python 環境 | Python 3.10.11 | |
| Git 環境 | その時の最新版 | |
| ffmpeg | その時の最新版 | 3D動画に元動画の音声を移したい場合に必要。 |
| Pytorch | ttorch==2.1.0(cu121) | |
| CUDA Toolkit | 12.1 | |
| cuDNN | 8.9.0以上 |
プログラム/モデルのインストール方法
| Step1 Python動作環境の構築 | ①Python 3.8.10の環境準備 ②Gitの環境準備 ③CUDA Toolkit 111のインストール ④cuDNN 8.0.5 ⑤FFMPEGのインストール(完成した3D動画に元の音声を書き込む場合) |
|---|---|
| Step2 プログラム のインストール | GitHubからVideo Depth Anything をインストール後、各種モジュールを pip コマンドにてインストールします。 |
| Step3 モデルのインストール | GitHubに公開されているページから学習済みモデルファイルをダウンロードし、所定のフォルダにコピーします。 |
インストール手順
Step1.Python動作環境の構築
「【最初の一歩】生成AI向けPython環境構築手順(スクリーンショットで解説)」の記載内容(①②③④)を実行してください。
Python環境構築手順の①~④をインストールしてください。
3D化した動画に元動画の音声を入れたい方は、手順⑦FFMPEGもインストールしてください。
Step2.Video Depth Anythingのインストール
あらかじめ、Video Depth Anythingをインストールするための任意のフォルダを作成しておきます。今回は、Oドライブの直下に VDAというフォルダを作成し、そこにインストールすることにします。
まず、コマンドプロンプトを開き、インストールしたいフォルダ(今回はOドライブ直下の VDAフォルダ)に移動し、次のコマンドを実行します。
git clone https://github.com/DepthAnything/Video-Depth-Anything.git
Video Depth Anythingのモジュールのインストールに成功したら、次のコマンドを実行してください。
cd Video-Depth-Anything
pip install -r requirements.txt
CPUだけで深度推定を行う場合はここで完了です。しかし、CPUだけだとわずか10秒の動画でさえ、数十分程度の処理時間が必要となります。
NVIDIAのGPUをお持ちの方は、下記のコマンドを実行してください。これでGPUが使えるようになります。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install xformers
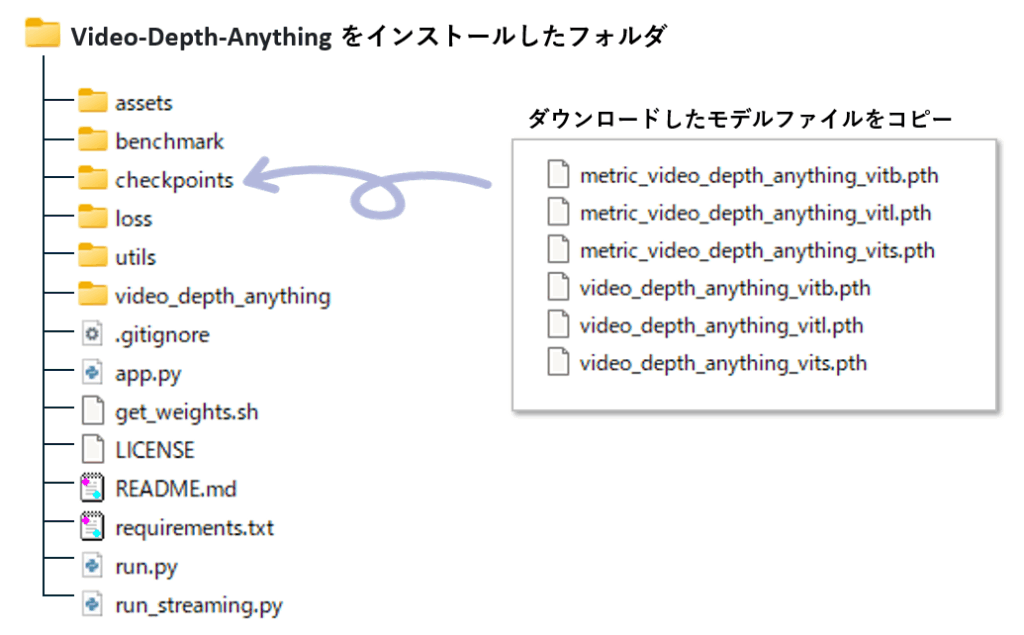
Step3.モデルのダウンロード&インストール
下記のダウンロードのリンクから、必要なモデルをダウンロードします。
モデルには「相対深度」と「メトリック」の2通りがありますが、今回は左側の「相対深度」を選んでください。
「相対深度」は2D画像を3D画像に変換する場合によく使われており、物体同士の前後関係や遠近感を推定する時に使います。
一方、「メトリック」は、カメラから物体までの実際の距離(メートルなど)を推定する際にもちいるもので、自動運転やロボティックスなど、正確な距離が必要な場合に適しています。
ダウンロードが完了したら、Video-Depth-Anything をインストールしたフォルダに checkpoints というフォルダを作り、そこにモデルファイルをコピーします。
使い方
コマンドプロンプトを開き、Video-Depth-Anythingをインストールしたフォルダに移動し、run.pyを実行することで、深度推定が行えます。
尚、--encoder には 3種類のモデル(vits、vitb 、vitl 詳細は後述)が指定できますが、省略するとvitlが使用されます。
python run.py --input_video 入力動画 --output_dir 出力先フォルダ --encoder モデルサイズ --grayscale
お使いのPC環境と動画の解像度、フレームレートによっては、run.py 実行中にメモリ不足によるエラーが発生する場合があります。この場合は、代わりに同梱されている run_streaming.py を使うと解消できる可能性が高いです。
下記は、Oドライブ直下の movie フォルダに置かれた test.mp4 を深度推定し、movieフォルダ直下に出力する例です。
パラメータの --encoder と --grayscale を 省略しています。
尚、test.mp4 は、動画の無料素材を公開している「動画AC」から入手した7秒のサンプル動画です。
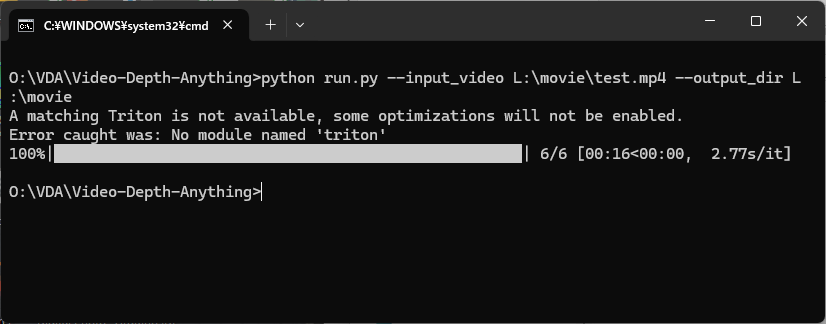
成功すると、ファイル名末尾に "_src" が付加された元動画のコピー(但し、音声は削除されている)と、”_vis"が付加された深度推定動画(深度マップ動画)が作成されます。
run.py には次のパラメータが指定できます。
| 引数 | 説明 | デフォルト / 備考 |
|---|---|---|
| --input_video | 入力動画のパス | 必須 |
| --output_dir | 出力結果を保存するディレクトリのパス | 必須 |
| --input_size | モデル推論時の入力サイズ | 518(初期値) |
| --max_res | モデル推論時の最大解像度 | 1280(初期値) |
| --encoder | 使用するエンコーダー: vits → Small vitb → Base vitl → Large | 任意 |
| --max_len | 入力動画の最大長さ(秒) -1で制限なし | 任意 |
| --target_fps | 出力動画のFPS -1で元のFPSを使用 | 任意 |
| --metric | Virtual KITTI と IRS データセットで学習したメトリック深度モデルを使用 | 任意 |
| --fp32 | 推論時に fp32 精度を使用 デフォルトは fp16 | 任意 |
| --grayscale | グレースケールの深度マップを保存(カラーパレット未使用) | 任意 |
| --save_npz | 深度マップを npz 形式で保存 | 任意 |
| --save_exr | 深度マップを exr 形式で保存 | 任意 |
モデルサイズ・fp16/32 における処理速度と深度推定品質の比較
処理速度と深度推定の品質は、モデルサイズと fp31/16 の指定で決まります。LargeモデルとBase モデルの処理時間差は歴然ですが、fp16/fp32 の処理時間差はほとんど変わらないか、半分弱になる程度の効果しかありませんでした。
今回のサンプル動画においては、一番最低品質(Small fp16)と最高品質(Large fp32)の深度推定の差はほぼ見つかりませんでした。従って Base モデル fp16 か Small fp16 で始めてみるのが良いかと思います。
ちなみに、下記は --grayscale を指定した深度推定動画です。3D化するには --grayscale を指定する方が良いとの記事があったので、今回は指定しました。
| モデルサイズ | 7秒の動画をfp16で推定した時間 | 7秒の動画をfp32で推定した時間 |
|---|---|---|
| small | 32秒 | 32秒 |
| base | 42秒 | 42秒 |
| large | 4分27秒 | 7分03秒 |
相対深度 Smallモデル fp16
相対深度 Baseモデル fp32
相対深度 Largeモデル fp32
高解像動画への対応
Video Depth Anything を使って フルハイビジョン以上の解像度を持つ動画から深度マップを作製する場合、解像度がハイビジョン(1280×720)にダウンサイジングされてしまいます。これだと、高画質の動画を3Dで楽しむことができません。
その対策として、深度マップだけを高解像化する方法があります。とはいうものの、単純なリサイズ(拡大)では、深度の境界がボヤけてしまい、立体化した際に物の輪郭が「溶けて」見えます。
そこで、元の フレームを「ガイド画像」として使用し、ボヤけた深度マップの境界をカラー画像のパキッとしたエッジに強制的に合わせる処理を挟みます。
下記は、これらの処理を実装したバッチ処理のサンプルプログラムです。refine_depth.pyという名前で保存してください。
このプログラムで高解像化した深度マップ動画と、オリジナル動画を用いることで、高解像度を保ったまま3D動画が作成できます。
| 引数フラグ | 設定項目 | 必須/任意 | デフォルト値 | 説明 |
--input | 入力ファイルパス | 必須 | - | 高解像度化したい元の動画(例: _vis.mp4)へのパスを指定します。 |
--output | 出力ファイルパス | 必須 | - | 処理後の動画を保存するパス(例: output_4k.mp4)を指定します。 |
--width | 出力横幅 | 任意 | 3840 | 出力動画の横ピクセル数。4Kなら3840、FHDなら1920を指定。 |
--height | 出力縦幅 | 任意 | 2160 | 出力動画の縦ピクセル数。4Kなら2160、FHDなら1080を指定。 |
import cv2
import numpy as np
import os
import sys
import argparse
def create_refined_depth_map(low_res_depth, original_frame):
h, w = original_frame.shape[:2]
if low_res_depth.dtype == np.uint8:
depth_16 = (low_res_depth.astype(np.float32) * (65535.0 / 255.0)).astype(np.uint16)
elif low_res_depth.dtype != np.uint16:
depth_16 = (low_res_depth * 65535).astype(np.uint16)
else:
depth_16 = low_res_depth
depth_resized = cv2.resize(depth_16, (w, h), interpolation=cv2.INTER_LANCZOS4)
guide = cv2.cvtColor(original_frame, cv2.COLOR_BGR2GRAY)
depth_f = depth_resized.astype(np.float32)
guide_f = guide.astype(np.float32)
refined_f = cv2.ximgproc.guidedFilter(guide=guide_f, src=depth_f, radius=10, eps=100.0)
return np.clip(refined_f, 0, 65535).astype(np.uint16)
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--input", required=True, help="Input video path")
parser.add_argument("--output", required=True, help="Output video path")
parser.add_argument("--width", type=int, default=3840)
parser.add_argument("--height", type=int, default=2160)
args = parser.parse_args()
cap = cv2.VideoCapture(args.input)
fps = cap.get(cv2.CAP_PROP_FPS)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(args.output, fourcc, fps, (args.width, args.height), True)
print(f"Processing: {args.input} -> {args.output} ({args.width}x{args.height})")
while cap.isOpened():
ret, frame = cap.read()
if not ret: break
ref_frame = cv2.resize(frame, (args.width, args.height), interpolation=cv2.INTER_LANCZOS4)
refined = create_refined_depth_map(frame, ref_frame)
final_vis_gray = (refined >> 8).astype(np.uint8)
final_vis = cv2.cvtColor(final_vis_gray, cv2.COLOR_GRAY2BGR)
out.write(final_vis)
cap.release()
out.release()
print("Done.")
if __name__ == "__main__":
main()深度推定の結果から3D動画を作成するプログラムの紹介

Video Depth Anything が生成する動画(xxx_src.mp4、xxx_vis.mp4)から、3D動画を生成するプログラム(スクリプト)を作りました。mk3d.py という名前です。
このスクリプトは、下記のルールに基づき、指定したフォルダ内のすべての動画を3D SBS形式の動画に変換し、別のフォルダに出力します。
- 動画ファイル名が
_srcで終わる場合- 同じ名前で末尾が
_visの動画が存在すれば、それを深度マップとして使用して3D化します。 _visが存在しない場合は、元動画の右半分を深度マップとして使用します。
- 同じ名前で末尾が
- 動画ファイル名が
_srcで終わらない場合- 動画の右半分を深度マップとして使用して3D化します。
audio_dir で指定したフォルダには、オリジナルの動画(音声が含まれている動画)が保存されているものとし、そこから音声を取り出して生成した3D動画に音声を上書きします。
python mk3d.py --input_dir 入力フォルダ --output_dir 出力フォルダ --audio_dir 音声フォルダ
| 引数 | デフォルト | 説明 |
|---|---|---|
| --input_dir | なし(必須) | 元動画が入ったフォルダパス |
| --output_dir | なし(必須) | VR動画の出力先フォルダ |
| --audio_dir | なし(必須) | 元動画の音声ファイルを置くフォルダ |
| --max_shift | 10 | 最大視差ピクセル数。大きいほど立体感が強くなる |
| --half_sbs | False | 指定すると幅半分SBSで出力。指定なしはフル幅SBS (※ --half_sbs True ではなく --half_sbs だけでOK) |
下記のソースコードを mk3d.py というファイル名で保存してください。
import os
import cv2
import numpy as np
import argparse
import subprocess
import shutil
import json
# ------------------------------
# フレーム読み込み関数
# ------------------------------
def read_frame_pair(src_video, depth_video=None):
"""
動画からフレームを読み込み、元画像と深度マップを返す関数
Parameters
----------
src_video : cv2.VideoCapture
元動画キャプチャ
depth_video : cv2.VideoCapture or None, optional
深度動画キャプチャ。None の場合は src_video の右半分を深度マップとして使用
Returns
-------
tuple
(src_frame, depth_frame)。フレーム末尾の場合は (None, None)
"""
ret_src, frame = src_video.read()
if not ret_src:
return None, None
if depth_video is None:
width = frame.shape[1] // 2
src_frame = frame[:, :width]
depth_frame = frame[:, width:]
else:
ret_depth, depth_frame = depth_video.read()
if not ret_depth:
return None, None
src_frame = frame
return src_frame, depth_frame
# ------------------------------
# VR用SBS画像生成関数
# ------------------------------
def create_vr_image(src_frame, depth_frame, max_shift=10, half_sbs=True, depth_min=0, depth_max=255):
"""
元画像と深度マップから左右視差を持つVR用SBS画像を生成
Parameters
----------
src_frame : np.ndarray
元画像
depth_frame : np.ndarray
深度マップ画像
max_shift : int
最大視差(ピクセル)
half_sbs : bool
Trueなら幅半分SBSで出力
depth_min : int
深度マップの最小値
depth_max : int
深度マップの最大値
Returns
-------
np.ndarray
左右視差付きSBS画像
"""
height, width = src_frame.shape[:2]
depth_gray = cv2.cvtColor(depth_frame, cv2.COLOR_BGR2GRAY).astype(np.float32)
depth_norm = np.clip((depth_gray - depth_min) / (depth_max - depth_min), 0, 1)
shift = depth_norm * max_shift
map_x, map_y = np.meshgrid(np.arange(width), np.arange(height))
map_x = map_x.astype(np.float32)
map_y = map_y.astype(np.float32)
map_x_left = map_x - shift
map_x_right = map_x + shift
left = cv2.remap(src_frame, map_x_left, map_y, interpolation=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REPLICATE)
right = cv2.remap(src_frame, map_x_right, map_y, interpolation=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REPLICATE)
if half_sbs:
left_half = cv2.resize(left, (width // 2, height))
right_half = cv2.resize(right, (width // 2, height))
combined = np.hstack((left_half, right_half))
else:
combined = np.hstack((left, right))
return combined
# ------------------------------
# VR動画生成関数
# ------------------------------
def generate_3d_sbs_video(src_video_path, depth_video_path=None, output_path="output.mp4", max_shift=10, half_sbs=True, depth_min=0, depth_max=255):
"""
元動画と深度動画からVR動画を生成
Parameters
----------
src_video_path : str
元動画ファイルパス
depth_video_path : str or None
深度動画ファイルパス。Noneの場合は src_video の右半分を使用
output_path : str
出力動画パス
max_shift : int
最大視差
half_sbs : bool
Trueなら幅半分SBSで出力
depth_min : int
深度マップ最小値
depth_max : int
深度マップ最大値
Returns
-------
str
生成したVR動画のパス
"""
video = cv2.VideoCapture(src_video_path)
depth = cv2.VideoCapture(depth_video_path) if depth_video_path else None
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH) // (2 if depth_video_path is None else 1))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = video.get(cv2.CAP_PROP_FPS)
frame_count = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
out_width = width if half_sbs else width * 2
out_height = height
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_path, fourcc, fps, (out_width, out_height))
frame_idx = 0
while True:
src_frame, depth_frame = read_frame_pair(video, depth_video=depth)
if src_frame is None:
break
vr_frame = create_vr_image(src_frame, depth_frame, max_shift=max_shift, half_sbs=half_sbs, depth_min=depth_min, depth_max=depth_max)
out.write(vr_frame)
frame_idx += 1
progress = (frame_idx / frame_count) * 100
print(f"\r進捗: {frame_idx}/{frame_count} ({progress:.2f}%)", end="")
video.release()
if depth:
depth.release()
out.release()
print(f"\nVR動画生成完了: {output_path}")
return output_path
# ------------------------------
# 音声有無チェック関数
# ------------------------------
def has_audio_stream(file_path):
"""
ffprobe を使って音声ストリームの有無を確認
Parameters
----------
file_path : str
チェックする動画ファイルパス
Returns
-------
bool
True なら音声あり、False なら音声なし
"""
cmd = [
"ffprobe", "-v", "error",
"-select_streams", "a",
"-show_entries", "stream=index",
"-of", "json",
file_path
]
result = subprocess.run(cmd, capture_output=True, text=True)
info = json.loads(result.stdout or "{}")
return "streams" in info and len(info["streams"]) > 0
# ------------------------------
# FFmpegで音声上書き(無音トラック対応)
# ------------------------------
def overwrite_audio_ffmpeg(video_path, audio_src_path, output_path):
"""
VR動画に音声を上書き。音声が無ければ無音トラックを追加
Parameters
----------
video_path : str
音声を上書きするVR動画
audio_src_path : str or None
音声元の動画。Noneの場合は無音トラックを追加
output_path : str
最終出力ファイル
"""
if not audio_src_path or not has_audio_stream(audio_src_path):
print(f"⚠ 音声ストリームが見つかりません → 無音トラックを追加")
cmd = [
"ffmpeg", "-y",
"-i", video_path,
"-f", "lavfi",
"-i", "anullsrc=channel_layout=stereo:sample_rate=44100",
"-c:v", "copy",
"-c:a", "aac",
"-shortest",
output_path,
]
subprocess.run(cmd, check=True)
return
cmd = [
"ffmpeg",
"-i", video_path,
"-i", audio_src_path,
"-c:v", "copy",
"-map", "0:v:0",
"-map", "1:a:0",
"-y",
output_path
]
subprocess.run(cmd, check=True)
print(f"音声上書き完了: {output_path}")
# ------------------------------
# 1本の動画を処理
# ------------------------------
def process_single_video(src_path, depth_path, audio_dir, output_dir, max_shift=20, half_sbs=False):
"""
1本の動画をVR化し、音声付きで出力
Parameters
----------
src_path : str
元動画パス
depth_path : str or None
深度動画パス
audio_dir : str or None
音声フォルダ。Noneの場合は無音トラック追加
output_dir : str
出力フォルダ
max_shift : int
最大視差
half_sbs : bool
Trueなら幅半分SBS
"""
os.makedirs(output_dir, exist_ok=True)
base_name = os.path.splitext(os.path.basename(src_path))[0]
# 元動画の末尾 "_src" を削除して "_3D" を付与
if base_name.endswith("_src"):
base_name = base_name[:-4]
base_name += "_3D"
# 一時出力ファイル
temp_output = os.path.join(output_dir, f"{base_name}_temp.mp4")
# 最終出力ファイル(_output を削除)
final_output = os.path.join(output_dir, f"{base_name}.mp4")
# VR動画生成
generate_3d_sbs_video(src_path, depth_video_path=depth_path, output_path=temp_output,
max_shift=max_shift, half_sbs=half_sbs)
# 音声上書き(audio_dir が None でも無音トラックで対応)
audio_src_path = os.path.join(audio_dir, os.path.basename(src_path).replace("_src", "")) if audio_dir else None
overwrite_audio_ffmpeg(temp_output, audio_src_path, final_output)
# 一時ファイル削除
os.remove(temp_output)
# ------------------------------
# バッチ処理関数
# ------------------------------
def batch_process_videos(input_dir, output_dir, audio_dir=None, max_shift=20, half_sbs=False):
"""
フォルダ内の動画をすべてVR化して出力
Parameters
----------
input_dir : str
元動画フォルダ
output_dir : str
出力先フォルダ
audio_dir : str or None
音声フォルダ。Noneの場合は無音トラックで出力
max_shift : int
最大視差
half_sbs : bool
Trueなら幅半分SBSで出力
"""
os.makedirs(output_dir, exist_ok=True)
files = os.listdir(input_dir)
processed = set()
for file in files:
if not file.endswith(".mp4"):
continue
file_path = os.path.join(input_dir, file)
base_name = file.rsplit(".mp4", 1)[0]
if base_name.endswith("_src"):
core_name = base_name[:-4]
vis_file = f"{core_name}_vis.mp4"
vis_path = os.path.join(input_dir, vis_file)
depth_video_path = vis_path if os.path.exists(vis_path) else None
print(f"処理中: {file} + {'_visあり' if depth_video_path else '右半分を深度として使用'}")
process_single_video(file_path, depth_video_path, audio_dir, output_dir, max_shift=max_shift, half_sbs=half_sbs)
processed.add(file)
if depth_video_path:
processed.add(vis_file)
elif file not in processed:
print(f"処理中 (右半分を深度として使用): {file}")
process_single_video(file_path, None, audio_dir, output_dir, max_shift=max_shift, half_sbs=half_sbs)
processed.add(file)
# ------------------------------
# コマンドライン引数
# ------------------------------
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Batch 3D SBS Video Generation with optional Audio")
parser.add_argument("--input_dir", required=True, help="入力動画フォルダ")
parser.add_argument("--output_dir", required=True, help="出力先フォルダ")
parser.add_argument("--audio_dir", help="オーディオフォルダ(省略可)")
parser.add_argument("--max_shift", type=int, default=10, help="最大視差")
parser.add_argument("--half_sbs", action="store_true", help="幅半分SBSで出力")
args = parser.parse_args()
batch_process_videos(args.input_dir, args.output_dir, args.audio_dir, max_shift=args.max_shift, half_sbs=args.half_sbs)
Video Depth Anything が簡単に使えるプログラムの紹介
Video Depth Anythingのインストール時に付属する run.py は、ファイルを1つづつ指定する必要があるため、フォルダ内の動画を一括処理するには不便です。そこで、depth_batch.py というプログラムを用意しました。
初期値としてBaseモデル、fp16 が選択されます。
python depth_batch.py --input_dir 動画フォルダ --output_dir 出力フォルダ
| パラメータ | デフォルト | 説明 |
|---|---|---|
| --input_dir | なし(必須) | 元動画が格納されているフォルダ |
| --output_dir | なし(必須) | 処理後動画を保存するフォルダ |
| --encoder | vitb | 使用するエンコーダ。vits(小)、vitb(中)、vitl(大) |
| --metric | False | metricモデルを使用するかどうか |
| --input_size | 518 | モデル入力サイズ(小さいほど高速) |
| --max_res | 1280 | 入力動画の最大解像度(縦横どちらか) |
| --fp32 | False | fp32精度で推論するかどうか(GPUメモリ消費増) |
| --grayscale | False | 深度可視化動画をグレースケールで保存 |
下記のソースコードを、depth_batch.py という名前で保存してください。
import os
import argparse
import torch
import numpy as np
from video_depth_anything.video_depth import VideoDepthAnything
from utils.dc_utils import read_video_frames, save_video
def process_videos(input_dir, output_dir, encoder_type='vitl', metric=False,
input_size=518, max_res=1280, fp32=False, grayscale=False):
os.makedirs(output_dir, exist_ok=True)
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
# --- モデルロード(1回だけ) ---
model_configs = {
'vits': {'encoder': 'vits', 'features': 64, 'out_channels': [48, 96, 192, 384]},
'vitb': {'encoder': 'vitb', 'features': 128, 'out_channels': [96, 192, 384, 768]},
'vitl': {'encoder': 'vitl', 'features': 256, 'out_channels': [256, 512, 1024, 1024]},
}
checkpoint_name = 'metric_video_depth_anything' if metric else 'video_depth_anything'
video_depth_anything = VideoDepthAnything(**model_configs[encoder_type], metric=metric)
video_depth_anything.load_state_dict(
torch.load(f'./checkpoints/{checkpoint_name}_{encoder_type}.pth', map_location='cpu'),
strict=True
)
video_depth_anything = video_depth_anything.to(DEVICE).eval()
# --- フォルダ内の動画を処理 ---
video_extensions = ('.mp4', '.mov', '.avi', '.mkv')
for file_name in os.listdir(input_dir):
if not file_name.lower().endswith(video_extensions):
continue
input_path = os.path.join(input_dir, file_name)
print(f"Processing: {input_path}")
frames, target_fps = read_video_frames(input_path, process_length=-1, max_res=max_res)
depths, fps = video_depth_anything.infer_video_depth(frames, target_fps, input_size=input_size, device=DEVICE, fp32=fp32)
# 保存
base_name = os.path.splitext(file_name)[0]
processed_video_path = os.path.join(output_dir, base_name + '_src.mp4')
depth_vis_path = os.path.join(output_dir, base_name + '_vis.mp4')
save_video(frames, processed_video_path, fps=fps)
save_video(depths, depth_vis_path, fps=fps, is_depths=True, grayscale=grayscale)
print(f"Saved: {processed_video_path}, {depth_vis_path}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Batch Video Depth Conversion")
parser.add_argument("--input_dir", required=True, help="入力動画フォルダ")
parser.add_argument("--output_dir", required=True, help="出力先フォルダ")
parser.add_argument("--encoder", default="vitb", choices=["vits", "vitb", "vitl"], help="使用するエンコーダ")
parser.add_argument("--metric", action="store_true", help="metric モデルを使用")
parser.add_argument("--input_size", type=int, default=518, help="入力サイズ")
parser.add_argument("--max_res", type=int, default=1280, help="最大解像度")
parser.add_argument("--fp32", action="store_true", help="fp32で推論")
parser.add_argument("--grayscale", action="store_true", help="グレースケールで保存")
args = parser.parse_args()
process_videos(
input_dir=args.input_dir,
output_dir=args.output_dir,
encoder_type=args.encoder,
metric=args.metric,
input_size=args.input_size,
max_res=args.max_res,
fp32=args.fp32,
grayscale=args.grayscale
)まとめ
Video Depth Anything を使えば、普通の2D動画が簡単に 3D化され、VRで遊べる動画 に大変身!
今回紹介した depth_batch.py や make3d.py を使えば、複数動画をまとめて処理できるので、VRでの没入体験もすぐにスタート可能です。
「いつもの動画が立体になって、手前に飛び出す感覚」を味わえば、きっとVR動画制作がもっと楽しくなります。ぜひ、手持ちの動画を3D化して、VRで新しい視覚体験を楽しんでみてください!


コメント