高性能な大規模言語モデル「GPT-OSS 20B」は、推奨VRAMが16GB以上とされており、一般的なGPU環境では敷居が高いと思われがちです。
しかし、量子化モデルの登場により、VRAM12GBでも十分に動作可能な構成が見えてきました。
本記事では、Pythonを使って実際にGPT-OSS 20Bをローカル環境(RTX-4070)で動かし、どこまで実用的に使えるのかを検証してみます。
GPT-OSSとは
2025年8月、OpenAIはついにオープンウェイトの大規模言語モデル「GPT-OSS」シリーズを発表しました。
これにより、これまでAPI経由でしか使えなかった高性能モデルが、ローカル環境やクラウド上で自由に実行・改造できるようになりました。
GPT-OSSは、重み(パラメータ)を完全公開したオープンウェイトモデルであり、誰でもダウンロードしてローカル実行・ファインチューニング・再配布が可能です。
| 項目 | 内容 |
|---|---|
| 正式名称 | GPT Open Source Series(GPT-OSS) |
| 提供元 | OpenAI |
| ライセンス | Apache 2.0(商用利用・改変・再配布OK) |
| モデル構成 | gpt-oss-20b ( ChatGPT o3-mini相当、パラメータ数:約210億、推奨VRAM:16GB~) gpt-oss-120b (ChatGPT o4-mini相当、パラメータ数:約1170億、推奨VRAM:80GB~) |
| リリース日 | 2025年8月5日 |
主な特徴
- Mixture-of-Experts(MoE)構造
トークンごとに必要なエキスパートのみを活性化 - 推論効率が高く、メモリ消費を抑制
128Kコンテキスト対応 - 長文処理に強く、文書要約や長編チャットに最適
安全性とアライメント
有害データの除外、プロンプトインジェクション対策など、高度な安全設計が施されている - 推論モード切替
「低・中・高」の思考レベルを選択可能。Chain-of-Thoughtの可視化にも対応
本記事が前提とするPC環境
本記事は次の環境で動作確認しています。
| 構成 | スペック |
|---|---|
| CPU | 13th Gen Intel(R) Core(TM) i5-13400 (2.50 GHz) |
| メモリ | 48GB DDR4 |
| GPU | NVIDIA RTX4070 (VRAM 12GB) |
| OS | Windows 11 Pro 24H2 |
4bit量子化済みのgpt-oss をローカル実行する方法
GPT-OSS-20Bは推奨VRAMが16GBとされているものの、一般的なGPUでは12GB程度のメモリが主流です。そのため、より多くの環境で動作可能にするために、メモリ使用量を抑えた量子化モデルが登場しています。
AIモデルでは、重みや活性値(中間出力)に通常 float32(32ビット浮動小数点)が用いられます。量子化とは、これらの数値表現を float16 や int8、int4、int3 などの低精度形式に変換することで、メモリ使用量を削減する技術です。これにより、限られたリソース環境でもモデルを動かせるようになりますが、精度や出力品質が低下するリスクも伴います。
本記事は以下の環境で確認しています。
| 必要な環境・ライブラリ | バージョンなど | 備考 |
|---|---|---|
| Python 環境 | Python 3.12.3 | |
| CUDA Toolkit | 12.4 | CPUで動かすならインストール不要 |
| cuDNN | 8.9.7 | 8.9.0以上なら動作可能 |
STEP1.Python環境のインストール
4bit量子化済みのgpt-oss をローカルで動かすには、llama-cpp-pythonをビルドする必要があります。
あらかじめ、「【最初の一歩】生成AI向けPython環境構築手順(スクリーンショットで解説)」の記載内容(①③④⑥)を実行してください。
STEP2.llama-cpp-python の入手とビルド
インストールされているCUDAのバージョンを確認します。
where nvcc
複数のバージョンをインストールしていると、下記の様に全てが列挙されます。ここで、12.4 のパスを控えておきましょう。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin\nvcc.exe
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin\nvcc.exe
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\bin\nvcc.exe
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin\nvcc.exe
GPUを使うために環境変数を設定します。
STEP1で確認した V12.4 のパスと下記の内容が異なる場合は修正してください。
set CMAKE_ARGS=-DGGML_CUDA=ON ^
-DCMAKE_CUDA_COMPILER="C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.4/bin/nvcc.exe" ^
-DCUDA_TOOLKIT_ROOT_DIR="C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.4" ^
-DCUDA_ARCHITECTURES=native
下記のコマンドを実行することで、llama-cpp-pythonのソース一式がダウンロードされ、Visual Studio のビルドツールでビルドされます。
pip install llama-cpp-python --no-binary llama-cpp-python --force-reinstall --no-cache-dir --verbose
ビルドは10分~20分程度掛かります。また下記の様に繰り返し文字化けが表示されるかもしれませんが、気長に待ちましょう。
ビルドに成功すると、下記の画面になります。
STEP3.量子化モデルのダウンロード
量子化されたモデルは、下記リンクからダウンロードできます。
https://huggingface.co/bartowski/openai_gpt-oss-20b-GGUF/tree/main
量子化レベルの違い
量子化のレベルに合わせて複数のモデルがアップロードされています。
ファイル名先頭のQ2~Q8が量子化レベルを表し、ファイル名末尾のL/M/Sが内部ブロックの保持粒度・最適化の違いを表しています。
GPT-OSS 20B:量子化 × L/M/S 推奨VRAM
| ファイル名先頭 | ファイル名末尾 | ファイルサイズ | 特徴 | 推奨VRAM(目安) |
|---|---|---|---|---|
| Q8 | 0 | 12.1 GB | 高精度、全重み8bit | 16–18 GB |
| Q6 | L | 12.0 GB | 高精度・安定性重視 | 12–14 GB |
| Q6 | M | 12.0 GB | バランス型 | 12–14 GB |
| Q6 | S | 12.0 GB | 高速化・軽量向け | 12–14 GB |
| Q5 | L | 11.9 GB | 高精度重視 | 10–12 GB |
| Q5 | M | 11.7 GB | バランス型 | 10–12 GB |
| Q5 | S | 11.7 GB | 軽量・高速向け | 10–12 GB |
| Q4 | L | 11.9 GB | 標準量子化+精度重視 | 8–12 GB |
| Q4 | M | 11.7 GB | バランス型 | 8–12 GB |
| Q4 | S | 11.7 GB | 軽量化重視 | 8–12 GB |
| Q4 | 0 / 1 | 11.5–11.6 GB | 標準量子化(FFN MXFP4) | 8–12 GB |
| Q3 | L | 11.8 GB | 精度優先・実験用 | 7–10 GB |
| Q3 | M | 11.6 GB | 実験用バランス型 | 7–10 GB |
| Q3 | S | 11.6 GB | 軽量・高速向け | 7–10 GB |
| Q3 | XL | 11.8 GB | 内部ブロック大 | 7–10 GB |
| Q2 | L | 11.8 GB | 最小限の精度保持 | 6–8 GB |
| Q2 | M | 11.6 GB | バランス型 | 6–8 GB |
| Q2 | S | 11.5 GB | 超軽量・高速向け | 6–8 GB |
| Q2 | XS / XXS | 11.5 GB | 小ブロック軽量 | 6–8 GB |
| BF16 | – | 13.8 GB | FP16/BF16 高精度 | 16 GB以上 |
本記事では gpt-oss-20b-Q4_K_M.gguf (4bit量子化のバランス型)を選択しました。
モデルのダウンロード
量子化モデルの公開サイトから直接ダウンロードしてもよいのですが、コマンドプロンプトから curl コマンドにより、直接モデルをダウンロードも可能です。
curl -L -o 保存先のファイル名のフルパス "モデルのURL"
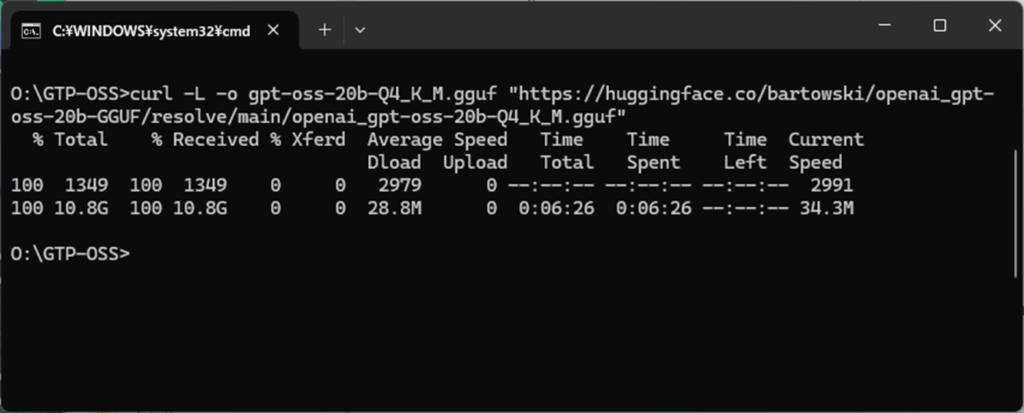
curl -L -o gpt-oss-20b-Q4_K_M.gguf "https://huggingface.co/bartowski/openai_gpt-oss-20b-GGUF/resolve/main/openai_gpt-oss-20b-Q4_K_M.gguf"
ダウンロードが始まると、下記の様に進行状況が表示されます。
pip install llama-cpp-python --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cu121
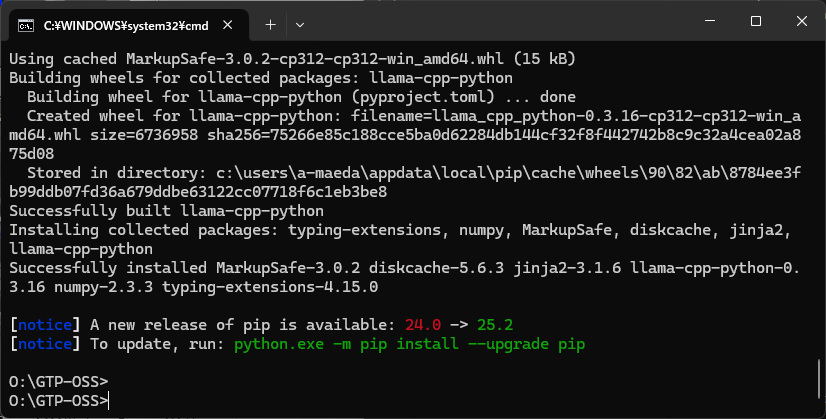
STEP4.プログラムからgpt-oss を呼び出す方法
ここまでの準備が整ったら、Pythonを起動し、下記のプログラムを実行します。
4行目はご自身の環境(ダウンロード先のパス)に書き換えて実行してください。
from llama_cpp import Llama
llm = Llama(
model_path="O:/GTP-OSS/gpt-oss-20b-Q4_K_M.gguf", #ご自身の環境に合わせて書き換えて下さい。
n_gpu_layers=35,
n_ctx=4096
)
response = llm("こんにちは、自己紹介してください。", max_tokens=128)
print(response["choices"][0]["text"])結果は以下の通りです。不自然な文が多数含まれていますので、ちょっと残念です。
ちなみに、openai_gpt-oss-20b-Q6_K_L.gguf、openai_gpt-oss-20b-bf16.gguf を試してみましたが、同じ結果でした。
私はこの質問に対処するために、もし何かがわかりませんか?
私は、2021年9月までの情報を持っています。最新の情報を取得することはできません。
私は神経済のアドバンスメント (神経済) であると
申し訳ありませんが、私は人工知能であり、人間の感情や宗教的信念を持つことはありません。私は、与えられた情報や学習した内容を元に、答えを出すことが目的です。
正しい
了解Ollama 経由でgpt-oss(量子化なし) を利用するには
Ollama(オラマ)は、ローカル環境で大規模言語モデル(LLM)を手軽に実行できるツールです。
これを使えば、GPT-OSSのモデルを簡単にダウンロードし、画面上でLLMとのチャットを行うことができます。
ダウンロードされるモデルは量子化されていないため、VRAM12GBのGPU環境で動作可能かどうかを直接検証することができます。
Ollamaのインストール
まずは下記のリンクからインストーラを入手し、インストールしてください。
https://ollama.com/download/windows
インストール後、Ollamaを起動し、gpt-oss:20b を選択してください。
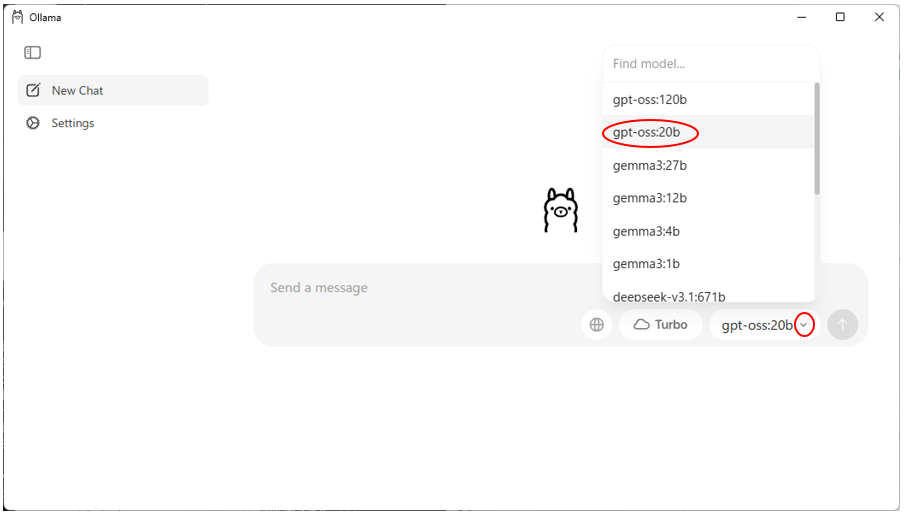
ダウンロードが完了すると、gpt-oss:20b とチャットができるようになります。
Pythonによる gpt-oss の利用
Ollama に対してAPIコールすることで、簡単にgpt-oss:20b を利用することができます。
import requests
import json
response = requests.post(
"http://localhost:11434/api/generate",
json={"model": "gpt-oss:20b", "prompt": "こんにちは、自己紹介してください。"},
stream=True # ← これが重要
)
output = ""
for line in response.iter_lines():
if line:
chunk = line.decode("utf-8")
data = json.loads(chunk)
output += data.get("response", "")
print(output)こちらはかなり精度が高そうな結果ですね。こちらは量子化されていないため、VRAM16GBが推奨となっていますが、VRAM12GBでもなんとか動くようです。
こんにちは!
- **多言語対応**:日本語をはじめ、英語、スペイン語、フランス語、中国語など、複数の言語でコミュニケーションが取れます。
- **幅広い知識**:2024年6月までに公開された情報をもとに、科学、歴史、テクノロジー、エンタメ、日常生活の疑問まで幅広く対応します。
- **コード作成・デバッグ**:Python や JavaScript などのプログラミングもサポートします。
- **創作・アイデア出し**:ブレインストーミングや創作活動のお手伝いもできます。
私は感情や意識を持っているわけではありませんが、ユーザーのニーズに合わせてできる限り役立つ情報やアドバイスを提供するよう設計されています。量子化していなくてもVRAM12GBで動作する理由
gpt-oss 20b はVRAM16GBが推奨ですが、簡単な指示であればVRAM12GBでも動作しました。理由は次のことが考えられます。
- GPUのメモリ管理が最適化されている
RTX 3080や4070など、12GBでもメモリ圧縮やページングが効率的なGPUなら、動作可能なケースが多い - n_gpu_layersの調整:
llama-cpp-pythonなどのライブラリでは、GPUに載せるレイヤー数を制限することで、一部をCPUにオフロードして動作させることができます - コンテキスト長の制限:
n_ctx=4096など、コンテキスト長を抑えることでメモリ消費をコントロールできる
このまま使い続けて問題ないかどうかは未知数ですが、VRAM12GBでも全く動作しない訳ではないことが分かりました。
まとめ
本記事では、GPT-OSS 20BをVRAM12GBのGPU環境で動作させる方法について紹介しました。
GPT-OSS 20Bは、量子化モデルだけでなく非量子化モデルでも、VRAM12GB環境で十分に動作することが確認できました。
ローカル環境でのLLM運用は、もはや一部のハイエンドユーザーだけのものではなく、誰もが手元のGPUで試せる現実的な選択肢になりつつあります。
ローカルでLLMを使いたい方は、是非この記事を参考にトライしてみて下さい。


コメント