映画『ターミネーター』で、T-800(アーノルド・シュワルツェネッガー)が電話越しに声を真似て人間を欺いたあの衝撃のシーン——
かつてはSFだったその技術が、今やPythonとAIで現実のものになりました。わずが数秒の音声データだけで、本物そっくりの声真似が可能です。
本記事では、音声変換AI「Seed-VC(Seed Voice Conversion)」をローカル環境に構築し、ゼロショットでの声真似・スタイル変換する方法を解説します。
GPUを活用することで、リアルタイムに近い処理速度と高品質な音声出力が可能になり、単なるボイスチェンジャーを超えた“声の再設計”が実現できます。
Pythonを使った声真似に興味のある方は、是非ご一読ください。
Seed-VCとは
Seed-VC(Seed Voice Conversion) は、音声変換(Voice Conversion, VC)技術の一つで、ある人物の音声を別の人物の声質に変換することを目的とした機械学習モデルです。
わずか1〜30秒の音声サンプルを参照するだけで、ファインチューニングなしに、別の話者の声に極めて近い音声を生成できます。
- 高品質な声質変換
ソース音声の内容(言葉や発音)を保持しつつ、ターゲット音声の声質や話者特性を忠実に再現します。 - ゼロショット変換
事前学習(ファインチューニング)が不要で、初めて聞く声でも即座に変換が可能です。 - 柔軟な応用範囲
通常の音声会話だけでなく、歌声変換やナレーションなど、さまざまな音声生成タスクに利用可能です。 - リアルタイム対応
推論速度が高速で、インタラクティブな応用も可能です。 - 制御パラメータによる出力調整
声質の類似度、音声の明瞭度、スタイル(感情・アクセント)の変換など、細かく出力を調整できます。 - GUI対応
初心者でも扱いやすいWebアプリが用意されています。
Seed-VCは、研究用途やエンターテインメント用途だけでなく、声優補助、音声アーカイブの声質再現、匿名化音声生成など幅広い応用が期待されている最先端の音声変換技術です。
Seed-VCの公式サイト
Seed-VCに関する説明とインストール方法については、GitHubの公式ページに記載されています。本記事は、ここに記載されている内容を分かり易くまとめたものです。
https://github.com/Plachtaa/seed-vc?tab=readme-ov-file
デモアプリ(HuggingFace)
Seed-VC の実力は、HuggingFaceに公開されているデモアプリですぐに確認できます。HuggingFace にログインしなくても試すことは可能ですが、1日の利用制限があります。
https://huggingface.co/spaces/Plachta/Seed-VC
インストールの前提条件
Seed-VCの公式GitHubページでは、Anaconda を使ったインストール方法が紹介されていますが、本記事ではWinPythonを使ったローカル環境へインストールする手順を紹介しています。
Python/CUDAのバージョン
動作に必要な環境は次の通りです。
| 必要な環境・ライブラリ | バージョンなど | 備考 |
|---|---|---|
| Python 環境 | Python 3.10.11 | |
| Git 環境 | その時の最新版 | |
| Pytorch | torch 2.7.1+cu118 | |
| CUDA Toolkit | 11.8 | CPUで動かすならインストール不要 |
| cuDNN | 8.9.7 | 8.9.0以上なら動作可能 |
インストール手順の概要
次の手順でインストールを行います。
| Step1 Python動作環境の構築 | ①Python 3.10.11の環境準備 ②Gitの環境準備 ③CUDA Toolkit 11.8のインストール(GPUを使う場合) ④cuDNN 8.9.7 |
|---|---|
| Step2 Seed-VCのインストール | GitHubからSeed-VCをインストール後、各種モジュールをインストール |
| Step3 各種モデルのインストール | 添付されているpython プログラムを実行することで、学習済みモデルがダウンロードされます。 |
インストール手順
Step1.Python動作環境の構築
「【最初の一歩】生成AI向けPython環境構築手順(スクリーンショットで解説)」の記載内容(①②③④)を実行してください。
Python環境構築手順の①~④をインストールしてください。
FFMPEGのインストールは不要です(使わないだけなので、インストールしても差し支えはありません)。
Step2.Seed-VCのインストール
あらかじめ、Seed-VCをインストールするための任意のフォルダを作成しておきます。今回は、Oドライブの直下に Seed-VCというフォルダを作成し、そこにインストールすることにします。
まず、コマンドプロンプトを開き、インストールしたいフォルダ(今回はOドライブ直下のSeed-VCフォルダ)に移動し、次のコマンドを実行します。
git clone https://github.com/Plachtaa/seed-vc.git
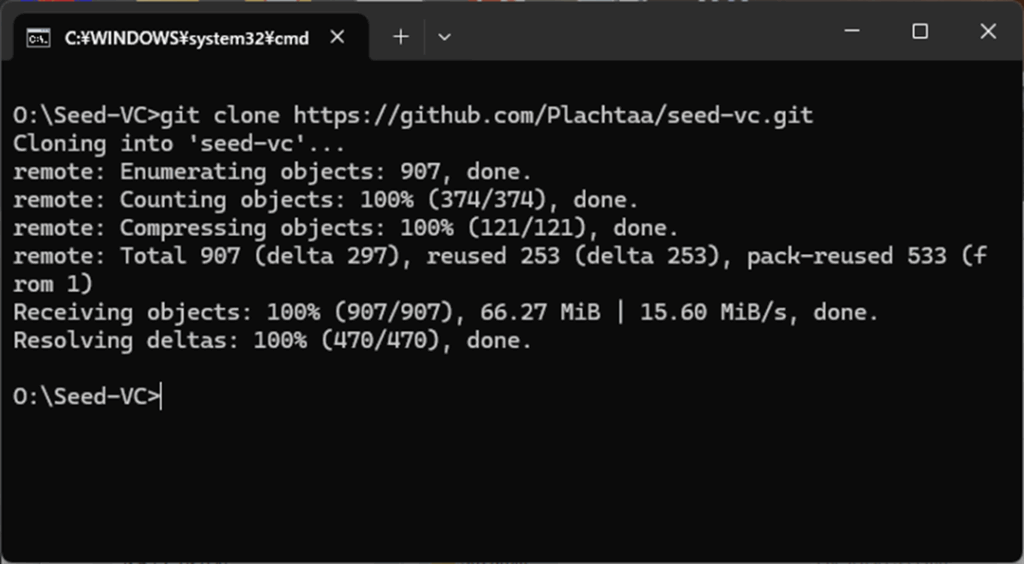
Seed-VCのモジュールがダウンロードできたら、次は必要なモジュールをインストールします。CPUだけで動作させたい場合は、これで完了です。但し、とてつもなく処理が遅いです。10秒程度の音声であっても30分~40分(Core-i5 13400 メモリ48GB)くらい掛かります 。
cd seed-vc
pip install -r requirements.txt
pip install triton-windows==3.2.0.post13
GPUを使う場合は、torch、torchvision、orchaudio を一旦アンインストールする必要があります。
pip uninstall torch torchvision torchaudio
何回か処理の継続を確認してくるので、その都度 y を入力します。
次に、GPU対応版の pytorch インストールします。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
CPU30分~40分掛かっていた処理時間が、わずか数秒(NVIDIA RTX-4070利用時)で終わるようになります。
Step3.各種モデルのインストール
必要なモデルは自動でダウンロードされるので、ここでは行いません。以上でモデルのインストールは完了です。
Seed-VCのフォルダ構成について
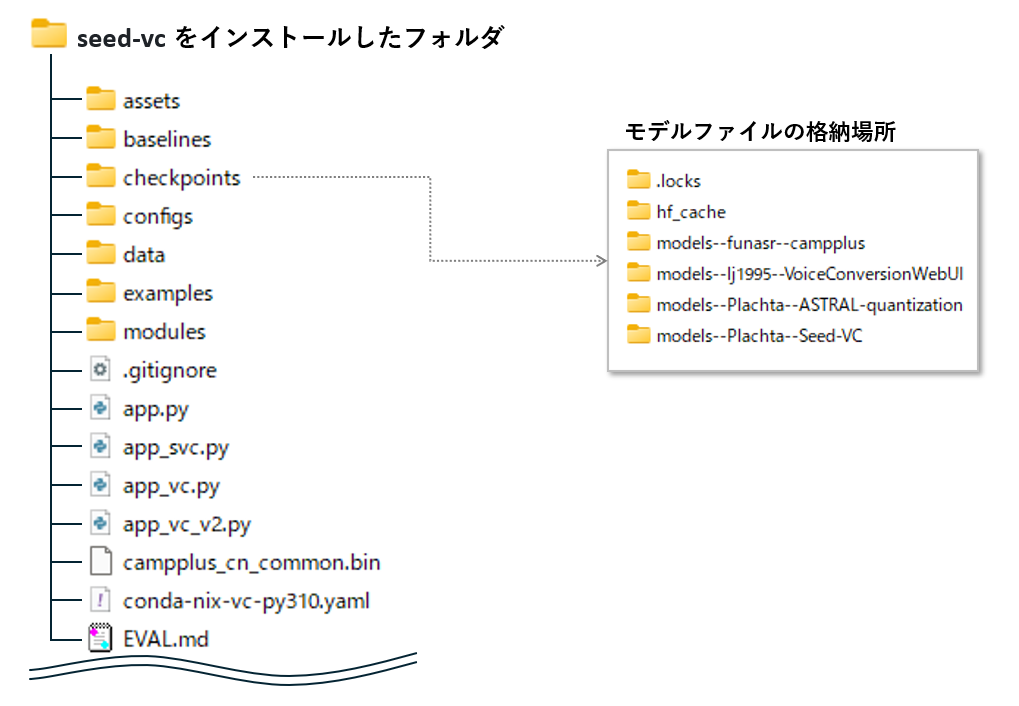
上図は、インストール後のフォルダ構成です。ここには、下記のファイルが格納されています。
| ファイル名 | 概要 |
|---|---|
| app.py | メインアプリケーション起動用 |
| app_vc.py | 音声変換(VC)用アプリ |
| app_vc_v2.py | V2モデル対応のVCアプリ |
| hf_utils.py | HuggingFace関連ユーティリティ |
| inference_v2.py | V2モデルの推論処理 |
| optimizers.py | 最適化アルゴリズム定義 |
| seed_vc_wrapper.py | Seed-VCのラッパー処理 |
| train.py | モデル学習用スクリプト |
| real-time-gui.py | GUIベースのリアルタイムVC |
| eval.py | 評価用スクリプト |
| camplusplus_cn_common.bin | モデル重みまたは特徴抽出用データ |
| conda-nix-vc-py310.yaml | Conda環境構成(Python 3.10) |
| EVAL.md | 評価手順や結果の記録 |
| LICENSE | ライセンス情報 |
| README.md | 英語のプロジェクト概要 |
| README-JA.md | 日本語のプロジェクト概要 |
| README-ZH.md | 中国語のプロジェクト概要 |
| requirements.txt | 通常環境用の依存パッケージ一覧 |
| requirements-mac.txt | macOS向け依存パッケージ一覧 |
Seed-VCプログラムの起動方法
コマンドプロンプトを開き、Seed-VCをインストールしたフォルダの直下に移動したあとで、各種プログラムを実行します。
例えば、Oドライブ直下に作成した Seed-VC フォルダにインストールしている場合は、次のようになります。
o:\
cd Seed-VC
cd seed-vc
声真似ファイルの作成方法
任意の音声ファイルに対して声真似の音声を作り出すことができます。Seed-VCは、コマンドラインによる変換とWeb画面を使った変換の2通りがありあます。
コマンドラインによる声真似変換
inference.py に音声ファイルを渡すと、簡単に声真似の音声ファイルが作成できます。
尚、--output は出力先フォルダです。出力ファイル名ではないことにご注意ください。
python inference.py --source 変換(声真似)したい音声 --target 声真似の元音声 --output 出力先フォルダ
--source <source-wav> # 変換したい入力音声ファイル
--target <referene-wav> # 声質をコピーする対象の参照音声ファイル
--output <output-dir> # 出力先ディレクトリ
--diffusion-steps 25 # 拡散ステップ数(推奨 30~50、数が多いほど高品質だが遅い)
--length-adjust 1.0 # 音声の長さ調整係数
--inference-cfg-rate 0.7 # 出力の制御強度(大きいほど参照の影響が強い)
--f0-condition False # F0 条件付け(歌声変換時は True)
--auto-f0-adjust False # ピッチを自動調整(通常は未使用)
--semi-tone-shift 0 # ピッチシフト(半音単位、歌声変換用)
--checkpoint <path-to-checkpoint> # 学習済みモデルのチェックポイントパス
--config <path-to-config> # モデルの設定ファイル
--fp16 True # 半精度計算を使用(GPUで高速化・省メモリ)例えば、Lドライブのaudioフォルダに置かれた 「東北ずん子.wav」を、「ずんだもん.wav」で声真似し、結果を L:\audioフォルダに出力するには、次のように記述します。
東北ずん子.wav(--source)
ずんだもん.wav(--target)
python inference.py --source L:\audio\東北ずん子.wav --target L:\audio\ずんだもん.wav --output L:\audio
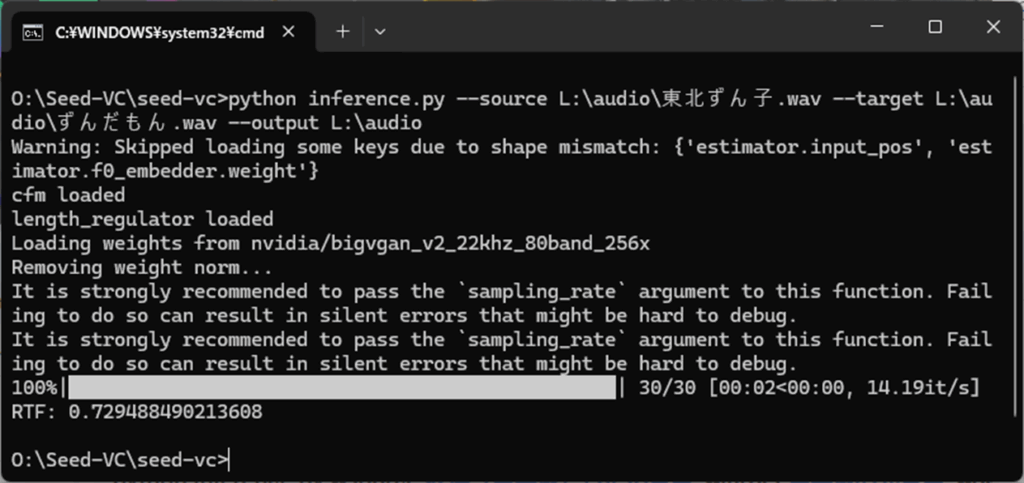
成功すると、--output で指定したフォルダに、vc_東北ずん子_ずんだもん_1.0_30_0.7.wav というファイルが出来上がります。わずか2秒の音声データだけで、ここまで声真似することができました。
vc_東北ずん子_ずんだもん_1.0_30_0.7.wav(--output)
Ceed-VCの改良版(V2)を使いたい場合、inference_v2.py を指定します。
python inference_v2.py --source 変換(声真似)したい音声 --target 声真似の元音声 --output 出力先フォルダ
--source <source-wav> # 変換したい入力音声ファイル
--target <referene-wav> # 声質をコピーする対象の参照音声ファイル
--output <output-dir> # 出力先ディレクトリ
--diffusion-steps 25 # 拡散ステップ数(推奨 30~50、数が多いほど高品質だが遅い)
--length-adjust 1.0 # 音声の長さ調整係数(V1と同じ)
--intelligibility-cfg-rate 0.7 # 音声内容の明瞭さ(0.0~1.0、値が大きいほどクリア)
--similarity-cfg-rate 0.7 # 声質の類似度(0.0~1.0、値が大きいほど参照に似る)
--convert-style true # ARモデルを使ったスタイル変換(感情・アクセントを反映)
--anonymization-only false # 参照音声を無視して匿名化するか(trueなら「平均的な声」化)
--top-p 0.9 # 出力多様性(ARモデル用、0.5~1.0推奨)
--temperature 1.0 # 出力のランダム性(0.7~1.2推奨)
--repetition-penalty 1.0 # 繰り返し抑制(1.0~1.5推奨)
--cfm-checkpoint-path <path-to-cfm-checkpoint> # CFMモデルのパス(空ならHuggingFaceから自動DL)
--ar-checkpoint-path <path-to-ar-checkpoint> # ARモデルのパス(空ならHuggingFaceから自動DL)
python inference_v2.py --source L:\audio\東北ずん子.wav --target L:\audio\ずんだもん.wav --output L:\audio
vc_v2_東北ずん子_ずんだもん_1.0_30_0.7.wav(--output)
Webアプリによる声真似変換
Hugging Face で公開されているデモ画面と同じWebアプリをローカルPC上で使うことができます。app_vc.py の引数に --enable-v1 と --enable-v2 の両方、またはどちらかを指定することでWebアプリが表示されます。
python app.py --enable-v1 --enable-v2
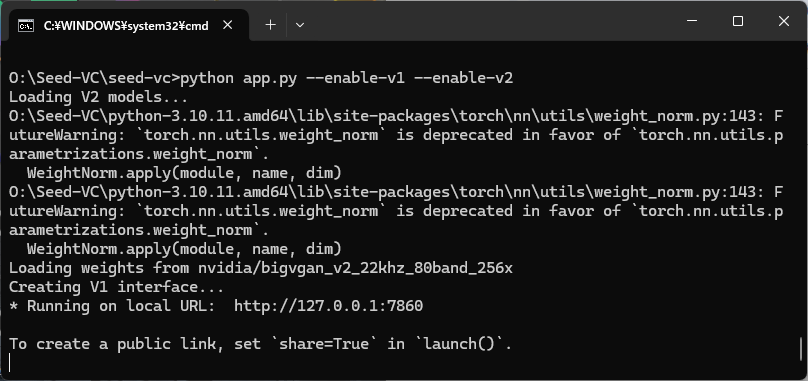
起動に成功すると、ブラウザから下記URLにアクセスすることで、Webアプリが表示されます。
http://127.0.0.1:7860
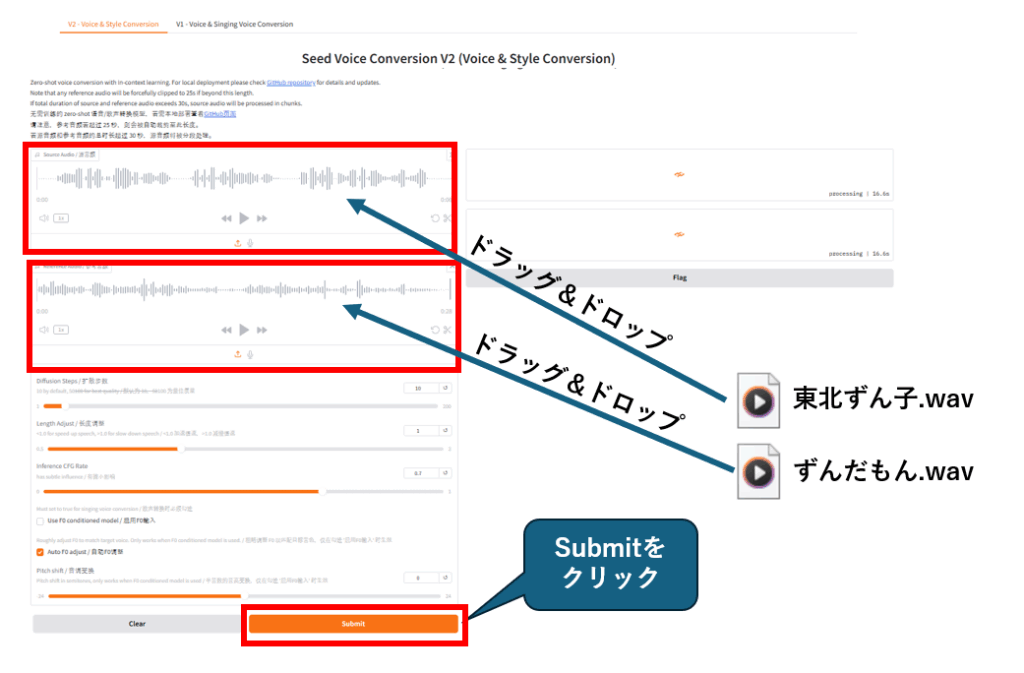
あとは、音声ファイルをドラッグ&ドロップし、Submit ボタンをクリックすると、声真似変換が行われます。
パラメータ概要と効果一覧(初期値ベース)
Diffusion Steps とIntelligibility CFG Rateの値を大きくすると、かなり品質は良くなります。
| パラメータ名 | 初期値 | 概要 | 音声への効果 |
|---|---|---|---|
| Diffusion Steps | 30 | 音声生成の反復ステップ数。高いほど精度向上。 | 品質は最低限。50〜60にすると滑らかさ・自然さが向上。高すぎると処理が重くなる。 |
| Length Adjust | 1 | 音声の再生速度調整。1が標準。 | <1でゆっくり、>1で早口になる。音質には直接影響しないが、自然さに関係。 |
| Intelligibility CFG Rate | 0.6 | 発音の明瞭さを制御。 | 低いと曖昧な発音になりやすく、1.0以上で明瞭さが増す。 |
| Similarity CFG Rate | 0.7 | 参照音声との類似度を制御。 | 値が大きいほど、音色や話し方が参照音声に近づく。 |
| Top-p | 0.9 | サンプリング時の確率分布の上位pを使用。 | 多様性と安定性のバランス。0.8〜0.95が一般的。 |
| Temperature | 0.1 | サンプリングのランダム性。低いほど決定的。 | 0.1は非常に安定だが、単調になりやすい。0.7〜1.0で自然な揺らぎが出る。 |
| Repetition Penalty | 1 | 同じ音の繰り返しを抑制。 | 1.0は無効。1.1〜1.3で繰り返しを減らし、滑らかさが向上する可能性あり。 |
| convert style/emotion/accent | ☑️ | スタイル・感情・アクセントの変換を有効化。 | より人間らしい抑揚や感情表現が可能になる。 |
| anonymization only | ⬜ | 匿名化モード。音声の個人特定要素を除去。 | 音質よりもプライバシー重視の設定。 |
まとめ
本記事では、音声変換AI「Seed-VC」をローカル環境に構築し、ゼロショットでの声真似やスタイル変換の手順を紹介しました。
わずか数秒の音声サンプルから、驚くほど自然な声質変換が可能です。但し、CPUだけだと遅すぎて実用的ではないため、GPUは必須です。
AIを使った声真似に興味のある方は、ぜひ自分の声や好きなキャラクターで試してみてください。

コメント