以前、[【Python】声真似AIボイスチェンジャーをローカル構築!Seed-VCでゼロショット音声変換に挑戦Python】] の記事で、音声変換の可能性をご紹介しました。
2024年に話題をさらったSeed-VCは、「音声データに対して声真似(=声質の入れ替え)」を行う存在でしたが、2026年1月に登場した「Qwen3-TTS」は、「声質を真似てテキストを読み上げる」、いわゆる音声合成(TTS)の技術です。
映画『ターミネーター』で、T-800が電話越しに声を真似て人間を欺いたように、今やたった3秒の音声データさえあれば、あなたの声質を学習し、自由自在に喋らせる次元にまで到達しました。
本記事では、この最新AI「Qwen3-TTS」をWindows11で動作させ、日本語環境で活用する方法を解説します。
Qwen3-TTSとは

Qwen3-TTS(Qwen3 Text-to-Speech)は、Alibaba CloudのQwenチームが開発した最新の音声合成(TTS)モデルです。 わずか3秒の音声サンプルを参照するだけで、事前学習なしに、その人物そっくりの声質で任意のテキストを読み上げることができます。
- 驚異的なゼロショット・ボイスクローン
事前学習(ファインチューニング)を一切必要とせず、初めて聞く声でも、たった3秒のサンプルから即座にクローン音声を生成します。 - 最新のLM(言語モデル)ベースのアーキテクチャ
従来の拡散モデル(Diffusion)とは異なり、離散マルチコードブックLMを採用。ボトルネックを排除し、人間の発話に近い極めて自然な抑揚と感情表現を実現しています。 - 超低遅延のストリーミング生成
1文字目から音声出力を開始できる「Dual-Track ストリーミング」に対応。エンドツーエンドで約97msという圧倒的な速さを誇り、AIとのリアルタイム対話に最適です。 - 10言語以上の多言語サポート
日本語、英語、中国語をはじめ、韓国語や欧州主要言語など、10種類以上の言語で高品質な音声を生成。言語をまたいだクロスリンガル合成も可能です。 - 直感的なプロンプト制御(Voice Design)
「落ち着いたプロフェッショナルな声」「元気で明るい少女の声」など、自然言語で指示を出すだけで、声質やキャラクターをゼロから設計できます。 - 日本語ローカライズと自動文字起こし(JP版)
日本語UIへの完全対応に加え、Whisperによる参照音声の自動文字起こし機能を搭載。複雑な手順なしで誰でも簡単にボイスクローンが楽しめます。
Qwen3-TTSは、単なる読み上げソフトを超え、動画ナレーション、ゲーム制作、パーソナルアシスタント、さらにはアクセシビリティ支援など、次世代の音声コミュニケーションを支える最先端の技術です。
Qwen3-TTSの公式ページ
Qwen3-TTSに関する説明とインストール方法については、GitHubの公式ページに記載されていますが、Linux上でのインストールを前提としており、そのままでWindows上で動作しません。
うれしいことに、hiroki-abe-58 さんがWindowsで動作するように手を加えたくださったバージョンが公開されており、オリジナルにはない文字お越し機能も追加されているので、本記事ではこちらを紹介させていただきました。
https://github.com/hiroki-abe-58/Qwen3-TTS-JP
インストールの前提条件
Qwen3-TTS-JPの公式GitHubページでは、Pythonに仮想環境(venv)を構築してインストールする方法が紹介されていましたが、本記事ではWinPythonを使ったローカル環境へのインストール方法を紹介しています。
Python/CUDAのバージョン
動作に必要な環境は次の通りです。
| 必要な環境・ライブラリ | バージョンなど | 備考 |
|---|---|---|
| Python 環境 | Python 3.10以上 | WinPython 3.12.3で動作確認済み |
| Git 環境 | その時の最新版 | |
| Pytorch | torch 2.6.0+cu124 | 最新のCUDA 12.4対応版を使用 |
| CUDA Toolkit | 12.4 | GPUは必須 |
| cuDNN | 9.1.0 | 8.9.0以上なら動作可能 |
| GPU | RTX 30/40/50シリーズが必須 | VRAM 8GB以上を推奨 |
インストール手順の概要
次の手順でインストールを行います。
| Step1 Python動作環境の構築 | ①Python 3.10.11の環境準備 ②Gitの環境準備 ③CUDA Toolkit 12.4のインストール ④cuDNN 9.1.0 |
|---|---|
| Step2 Seed-VCのインストール | GitHubからQwen3-TTS-JPをインストール後、各種モジュールをインストール |
| Step3 各種モデルのインストール | 添付されているWebアプリの初回起動時、モデルが自動でダウンロードされます。 |
インストール手順
Step1.Python動作環境の構築
「【最初の一歩】生成AI向けPython環境構築手順(スクリーンショットで解説)」の記載内容(①②③④)を実行してください。
Python環境構築手順の①~④をインストールしてください。
FFMPEGのインストールは不要です(使わないだけなので、インストールしても差し支えはありません)。
Step2.Qwen3-TTS-JPのインストール
あらかじめ、Qwen3-TTSをインストールするための任意のフォルダを作成しておきます。今回は、Oドライブの直下に Qwen3-TTSというフォルダを作成し、そこにインストールすることにします。
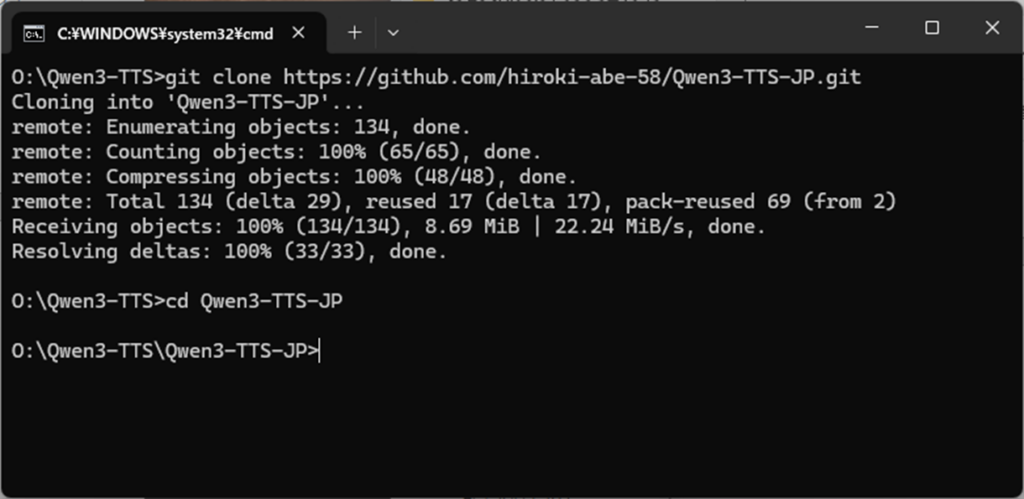
まず、コマンドプロンプトを開き、インストールしたいフォルダ(今回はOドライブ直下のQwen3-TTSフォルダ)に移動し、次のコマンドを実行します。
git clone https://github.com/hiroki-abe-58/Qwen3-TTS-JP.git
cd Qwen3-TTS-JP
Qwen3-TTSのモジュールがダウンロードできたら、次は必要なモジュールをインストールします。
pip install -e .
pip install faster-whisper
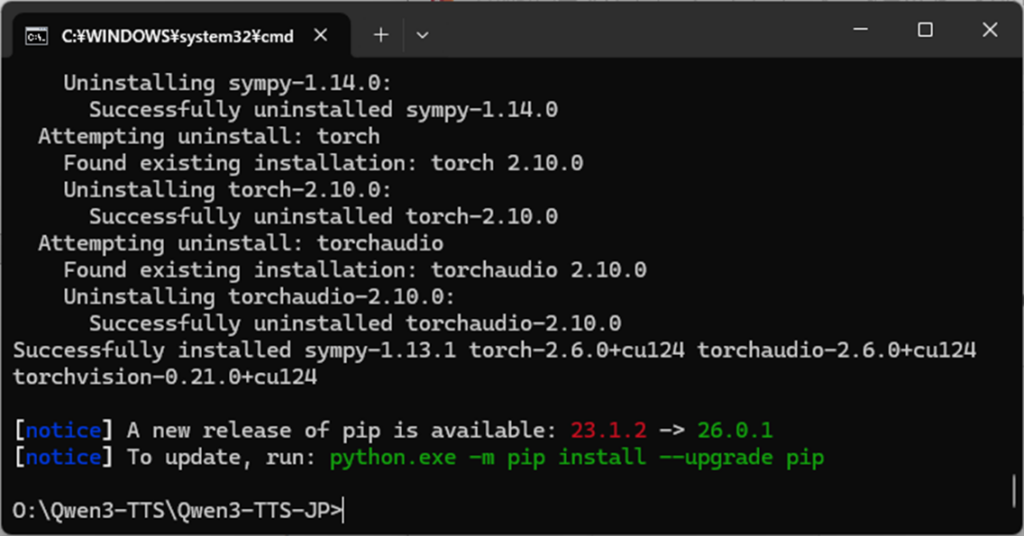
GPUを使いたいので、torch、torchvision、torchaudio をインストールします。お使いのGPUが RTX 30/40シリーズの場合と、RTX 50シリーズの場合では、インストール方法が異なるのでご注意ください。
# RTX 30/40 シリーズを使う場合
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
# RTX 50 シリーズを使う場合
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128
Step3.各種モデルのインストール(ここでは不要)
必要なモデルは自動でダウンロードされるので、ここでは行いません。
Qwen3-TTSのフォルダ構成について
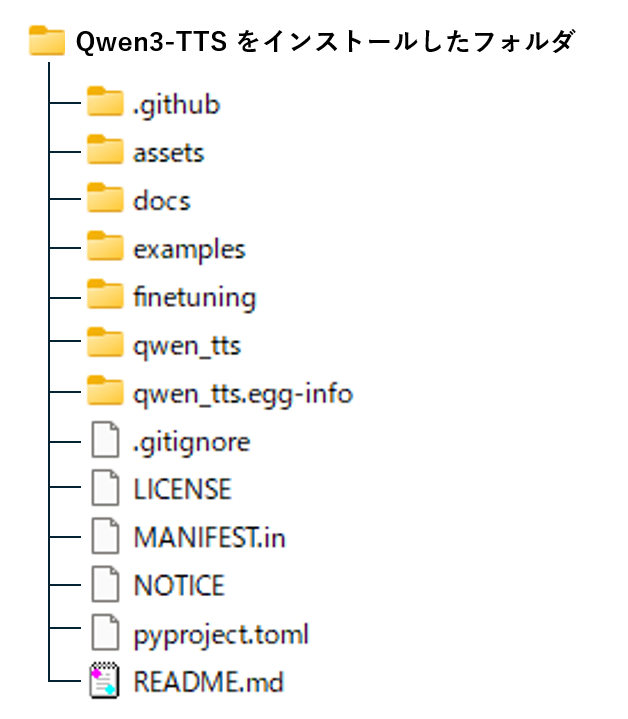
インストールが完了すると、下記のフォルダ構成が出来上がります。
Qwen3-TTSのWebアプリのソースコードは、qwen_tts フォルダ内に格納されています。
Qwen3-TTSプログラムの起動方法
コマンドプロンプトを開き、Qwen3-TTSをインストールしたフォルダの直下に移動したあとで、Webアプリを実行します。
Webアプリは次のパラメータで起動します。
qwen-tts-demo モデルパス --ip アドレス --port ポート番号 --no-flash-attn
モデルパスに指定するモデルは、次の中から指定します。
| モデル名 | 概要 |
|---|---|
| Qwen3-TTS-12Hz-1.7B-VoiceDesign | ユーザーが提供した説明に基づいて音声設計を実行します。 |
| Qwen3-TTS-12Hz-1.7B-CustomVoice | ユーザーの指示により対象の音色のスタイルを制御できます。性別、年齢、言語、方言のさまざまな組み合わせをカバーする 9 つのプレミアム音色をサポートします。 |
| Qwen3-TTS-12Hz-1.7B-Base | ユーザーのオーディオ入力から 3 秒間の高速音声クローンを作成できる基本モデル。他のモデルの微調整 (FT) に使用できます。 |
| Qwen3-TTS-12Hz-0.6B-CustomVoice | 性別、年齢、言語、方言のさまざまな組み合わせをカバーする 9 つのプレミアム音色をサポートします。 |
| Qwen3-TTS-12Hz-0.6B-Base | ユーザーのオーディオ入力から 3 秒間の高速音声クローンを作成できる基本モデル。他のモデルの微調整 (FT) に使用できます。 |
今回は声真似がしたいので、Qwen3-TTS-12Hz-1.7B-Base を使用します。
具体的には以下のコマンドを実行します。
o:\
cd Qwen3-TTS
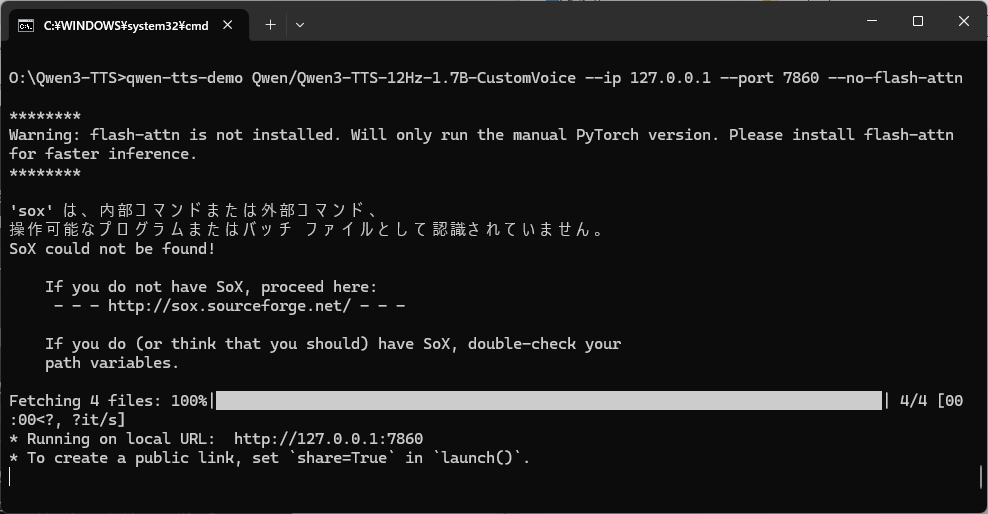
qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-Base --ip 127.0.0.1 --port 7860 --no-flash-attn
声真似(ボイスクローン)を行う場合、モデルはBase が前提ですが、CustomVoice や VoiceDesign を選ぶこともできます。試してみた結果、やはりBase が最も品質が良く、CustomVoice や VoiceDesign は声質もさることながら、イントネーションも少し片言っぽくなりました。
実行すると下記のような画面が表示され、モデルが自動ダウンロードされます。
ダウンロードが終わったら、 お使いのブラウザから下記のURLでアクセスできます。
http://172.0.0.1:7860
Qwen3-TTSをインストールした時点で、WinPythonのScriptsフォルダ(今回の場合は python-3.12.3.amd64\Script 内)にqwen-tts-demo.exe が自動生成されます。
従って、WinPythonのパスさえ通っていれば、どこからでも起動できます。
ブラウザでアクセスすると、下記の画面が表示されるはずです。
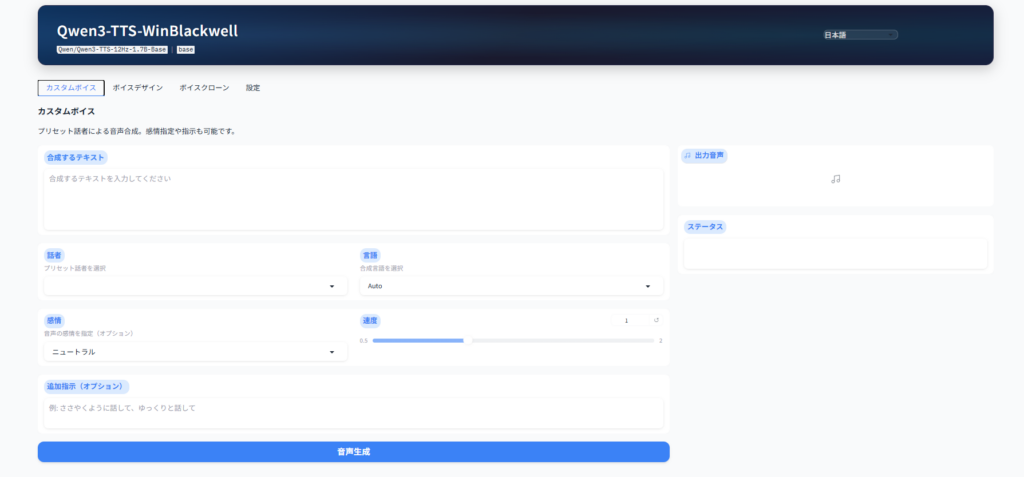
画面の説明
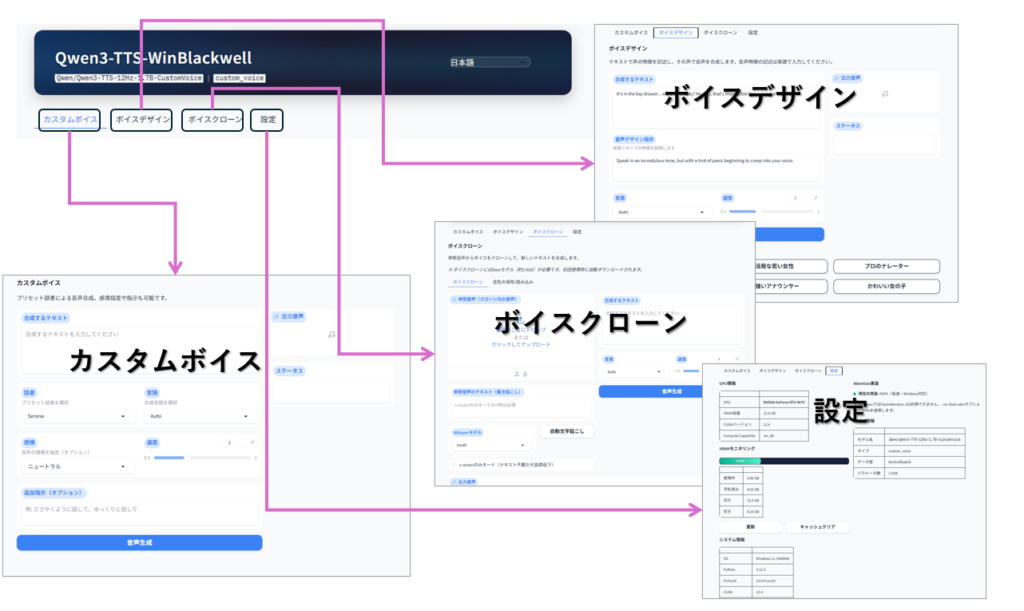
| タブ名 | 画面項目 | 用途と機能 |
|---|---|---|
| カスタムボイス | 合成するテキスト、話者、感情、追加指示、言語、速度、出力音声、ステータス | 登録済みボイス(9種類)から一人を選んで音声合成。感情の指定、話し方の指示が可能。 |
| ボイスデザイン | 合成するテキスト、音声デザイン指示、言語、速度、出力音声、プリセットボイス | 話し方や声質の指示で任意テキストの音声合成が可能。入力不可、英語のみ対応。単なるデモ画面の位置づけ。 |
| ボイスクローン | 参照音声、参照音声テキスト、自動文字起こし、合成するテキスト、Whisperモデル、x-vectorのみモード、音色ファイル保存、音色ファイルアップロード、言語、速度、出力音声、ステータス、 | アップロードした音声から声質モデルを作成し、任意のテキストで音声合成が可能。声質モデルはファイル保存し、呼び出して再利用することが可能。 |
| 設定 | GPU情報、システム情報、モデル情報、技術情報更新、VRAMモニタリング、キャッシュクリア | GPUを含むシステム使用状況のモニタリング画面。 |
ボイスクローン・音声合成タブ
この画面は、声色の学習と音声合成を簡単に行うための画面です。
出来上がった声色モデルはどこにも保存されず、画面のリロード、またはプログラム終了時に破棄されます。
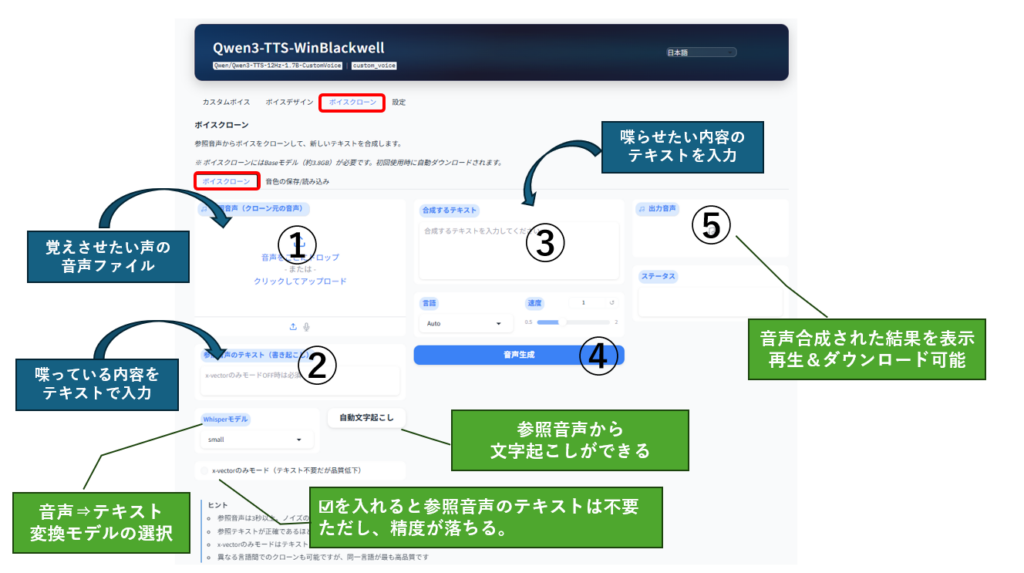
- 覚えさせたい声の音声ファイル(3秒~)を①にドラッグ
- 音声ファイルの内容を②にテキストで入力(面倒な場合は自動文字起こしを利用)
- 喋らせたい内容のテキストを③に入力
- ④の音声再生ボタンをクリック
- 生成された音声合成データを⑤で再生&ダウンロード
音声ファイルの内容をテキストとして入力することで、生成される音声の品質が上がります。
「自動文字起こし」で精度の高い文字起こしが可能なので、極力②は入力しましょう。
自動文字起こしの際は、次の中からモデル(Whisperモデル)が選べます。
・tiny- 最速かつ最小(39Mパラメータ)
・base- 高速(74Mパラメータ)
・small- バランス型(244Mパラメータ)*デフォルト
・medium- 高精度(769Mパラメータ)
・large-v3- 最高の精度(1550Mパラメータ)
ボイスクローン・声色の保存・読込タブ
学習させた声色モデルの保存し、読み込んで再利用することが可能です。前述の「音声合成タブ」とは異なり、一旦音色モデルを保存し、それを読み込ませないと音声合成できません。
作成した声色モデルを使いまわして音声合成する場合に使用します。
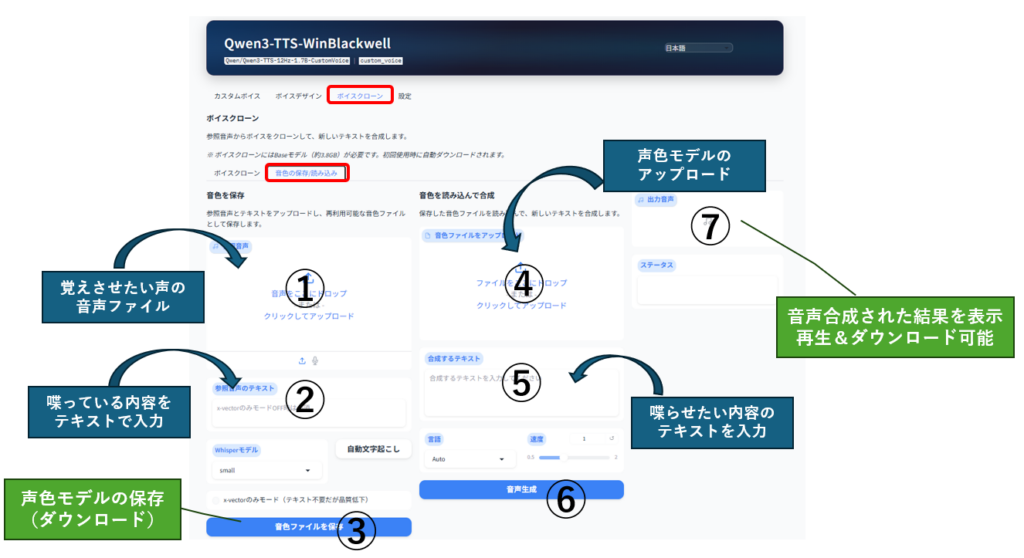
音色モデルの作成と保存
声色モデルの作成と保存は画面左側を使います。
- 覚えさせたい声の音声ファイル(3秒~)を①にドラッグ
- ②に音声ファイルの内容をテキストで入力
- ③の「音色ファイルを保存ボタン」をクリック
以上の操作で音声ファイルを保存ボタンの直下に音色ファイルのリンクが表示されるので、これをクリックしてダウンロードしてください。
音色モデルの読込と音声合成
声色モデルの作成と保存は画面左側を使います。
- 音色ファイルを④にドラッグ
- 喋らせたい内容のテキストを入力⑤に入力
- ⑥の「音声再生ボタン」をクリック
- 生成された音声合成データを⑦で再生&ダウンロード
Qwen3-TTSとSeed-VCの音声比較
Seed-VCで実験した音声ファイル(「東北ずん子.wav」「ずんだもん.wav」)を使って、生成される音声品質を比較しました。
学習させたい音声ファイル「ずんだもんwav 」は2秒しかありませんが、Qwen3-TTSで一応検証はできました。
まずは、ずんだもん.wav(--target)の音声です。
下記は、Qwen3-TTSによる音声合成、Seed-VC V1とV2それぞれの音声変換結果です。
Qwen3-TTS
Seed-VC V1
Seed-VC V2
いずれも元が音声合成された音声データであるため、イントネーションは怪しいですが、Seed-VCがもとの音声を変換しているのに比べ、Qwen3-TTSはゼロから生成しているため、デジタル感が少ない気がします。
まとめ
今回紹介した「Qwen3-TTS」は、これまでのボイスチェンジャー的な「声の入れ替え(Seed-VC)」とは異なり、「声のコピーを自由に喋らせる」というアプローチになります。
最後に、これら2つの最新AIをどう使い分けるべきかをまとめておきます。
- Qwen3-TTSを選ぶべきシーン
- 動画のナレーションやゲームのセリフなど、大量のテキストを読み上げさせたいとき。
- 3秒のサンプルから、その人の「分身」に好きなことを喋らせたいとき。
- 低遅延なリアルタイム対話を楽しみたいとき。
- Seed-VCを選ぶべきシーン
- 自分の喋り方や歌い方の「ニュアンス」を保ったまま、声質だけをキャラに変えたいとき。
- リアルタイムボイスチェンジャーとして、VRChatや配信で活用したいとき。
かつて映画の中でしか見られなかった「声の偽装」や「完璧なボイスクローン」は、いまやRTX 4070クラスのPCがあれば、自宅で数分で構築できる時代になりました。
Qwen3-TTSは、日本語対応(JP版)のおかげで導入のハードルも劇的に下がっています。皆さんもぜひ、自分の声をクローンして、そのクオリティの高さを体感してみてください。

コメント