欠損画像の修復やロゴの差し替えなど、最近はAIが“それっぽく”補完してくれる時代になりました。
でも実際のところ、技術としてどこまで使えるのでしょうか?
この記事では、pix2pixとCycleGANという画像変換モデルのインストール方法、使い方に加え、自前の画像を使った欠損部補完(モザイク化された口元を復元)における性能を検証してみました。
画像変換とは
画像変換とは、ある画像を別の形式・スタイル・構造に変換する技術です。
たとえば、白黒画像をカラー化したり、線画をリアルな写真風に変えたり、欠損部分を自然に補完したりすることができます。
この分野で代表的なモデルが pix2pix と CycleGAN。どちらも GAN(敵対的生成ネットワーク) をベースにした画像変換モデルですが、学習方法や得意分野が異なります。
pix2pixとは?(教師あり画像変換)

pix2pix は、画像から画像への変換を行う 教師ありの画像変換モデル です。
2017年に Isola らによって提案されたこのモデルは、Conditional GAN(cGAN) をベースにしており、入力画像に対応する「正解画像」を学習することで、構造的に忠実な変換を実現します。
| 特徴 | 用途 |
|---|---|
| - ペア画像が必要(入力+正解) - 構造の忠実な再現が得意 - GeneratorにU-Net構造を採用 - PatchGAN Discriminatorで局所判定 - L1損失 + Adversarial損失で学習 | - 白黒画像 → カラー画像 - セグメンテーションマップ → 写真 - 欠損画像 → 補完画像(inpainting) - スケッチ → 実写風イメージ - 図面 → 完成図の補完 - ロゴの一部復元・再構成 |
CycleGANとは?(教師なし画像変換)
CycleGAN は、ペア画像が存在しない状況でも画像変換を可能にする 教師なしの画像変換モデル です。
2017年に Jun-Yan Zhu らによって提案され、Cycle-Consistent Adversarial Networks という構造を持ち、ドメインAとBの画像群だけで学習を行います。
このモデルは、双方向の変換(A→B、B→A)を同時に学習し、変換後の画像を元に戻すことで「変換の一貫性(Cycle Consistency)」を保ちます。
また、Identity Loss によって不要な変化を抑え、スタイル変換の自然さを向上させます。
| 特徴 | 用途 |
|---|---|
| - ペア画像不要(非対応画像群でOK) - スタイル・質感の変換が得意 - 双方向変換(A→B、B→A)を同時に学習 - Cycle Consistency Loss による一貫性保持 - Identity Loss で不要な変化を抑制 | - 馬 ↔ シマウマ(模様の変換) - 写真 ↔ 絵画(スタイル転写) - 季節変換(夏 ↔ 冬) - ロゴのスタイル変換(フラット ↔ グラデ) - 顔属性変換(笑顔 ↔ 怒り顔、眼鏡あり ↔ なし) - 図面 ↔ 手描き風スケッチ |
pytorch-CycleGAN-and-pix2pix 公式サイト
CycleGAN と pix2pix は本来それぞれ独立したモデルとして GitHub 上で公開されていますが、今回紹介するGitHubのURL(下記)から、両方のモデルを同時に入手・利用することが可能です。
インストールの前提条件
pytorch-CycleGAN-and-pix2pixのページでは、モデルのダウンロード方法とデモプログラムの使い方が記載されていますが、本記事はこれを分かり易く解説したものです。
Python/CUDAのバージョン
動作に必要な環境は次の通りです。
| 必要な環境・ライブラリ | バージョンなど | 備考 |
|---|---|---|
| Python 環境 | Python 3.8.10 | |
| Git 環境 | その時の最新版 | |
| Pytorch | torch 2.4.1 | |
| CUDA Toolkit | 12.1 | CPUで動かすならインストール不要 |
| cuDNN | 9.0.1 | 8.9.0以上なら動作可能 |
インストール手順の概要
次の手順でインストールを行います。
| Step1 Python動作環境の構築 | ①Python 3.8.10の環境準備 ②Gitの環境準備 ③CUDA Toolkit 12.1のインストール(GPUを使う場合) ④cuDNN 9.0.1 |
|---|---|
| Step2 SCUNet のインストール | GitHubからpytorch-CycleGAN-and-pix2pix をインストール後、各種モジュールをインストール |
| Step3 学習済みモデルのインストール | GitHubに公開されている学習済みモデルとテスト用データセットをダウンロードします。 |
インストール手順
Step1.Python動作環境の構築
「【最初の一歩】生成AI向けPython環境構築手順(スクリーンショットで解説)」の記載内容(①②③④)を実行してください。
Python環境構築手順の①~④をインストールしてください。
FFMPEGのインストールは不要です(使わないだけなので、インストールしても差し支えはありません)。
Step2.pytorch-CycleGAN-and-pix2pixのインストール
あらかじめ、SCUNet をインストールするための任意のフォルダを作成しておきます。今回は、Oドライブの直下に DeNiseというフォルダを作成し、そこにインストールすることにします。
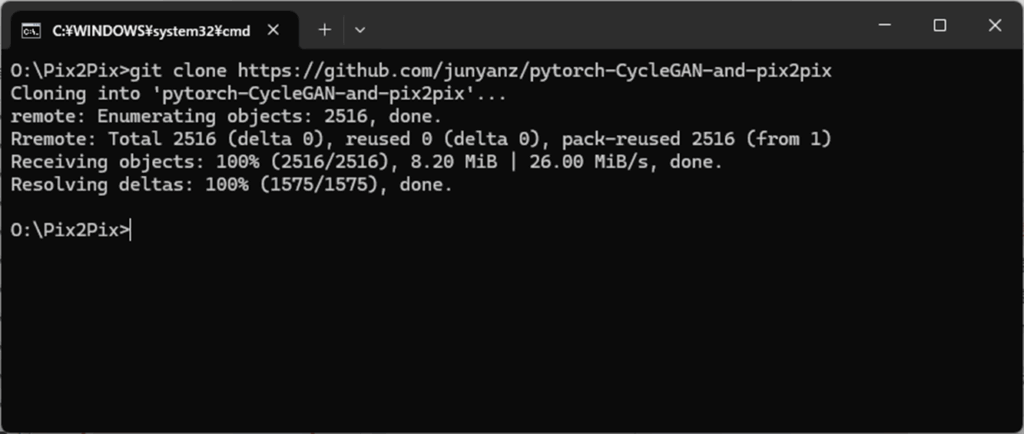
まず、コマンドプロンプトを開き、インストールしたいフォルダ(今回はOドライブ直下のSCUNet フォルダ)に移動し、次のコマンドを実行します。
git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
pytorch-CycleGAN-and-pix2pixのモジュールがインストールに成功したら、次のコマンドを実行してください。
cd pytorch-CycleGAN-and-pix2pix
pip install -r requirements.txt
pip install numpy Pillow matplotlib opencv-python scikit-image requests
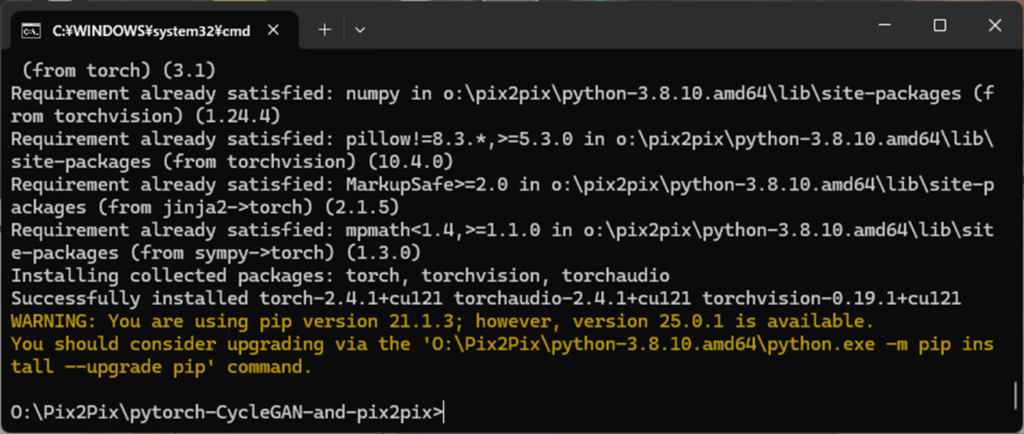
pytorch-CycleGAN-and-pix2pix をCPUのみで動作させる場合はこれで完了ですが、GPUを使う場合は一旦 pytorch をアンインストール後、GPU対応版のpytorch をインストールする必要があります。
具体的には、下記のコマンドを実行してください。
pip uninstall torch torchvision torchaudiopip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
Step3.学習済みモデルとテスト用データセットのインストール
続けて、モデルファイルをダウンロードします。
pytorch-CycleGAN-and-pix2pix のGitHub公式ページでは、Linuxのbashコマンドでモデルファイルをダウンロードしていますが、Gitの環境準備(GitPortableのインストール)が完了している場合は、Windows上でもbashコマンドをそのまま利用可能です。
まず、次のコマンドでCycleGANの学習済みモデルとテスト用のデータセットをダウンロードします。
bash ./scripts/download_cyclegan_model.sh horse2zebra
bash ./datasets/download_cyclegan_dataset.sh horse2zebra
次に、pix2pixの学習済みモデルとテスト用のデータセットをダウンロードします。
bash ./scripts/download_pix2pix_model.sh facades_label2photo
bash ./datasets/download_pix2pix_dataset.sh facades
以上でインストールは完了です。
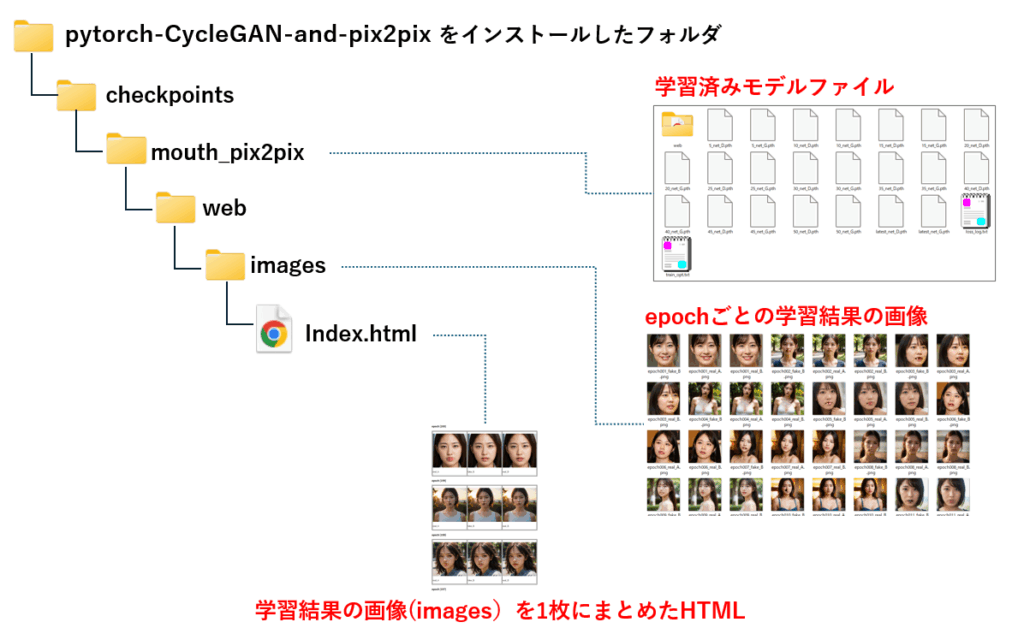
pytorch-CycleGAN-and-pix2pixフォルダ構成について
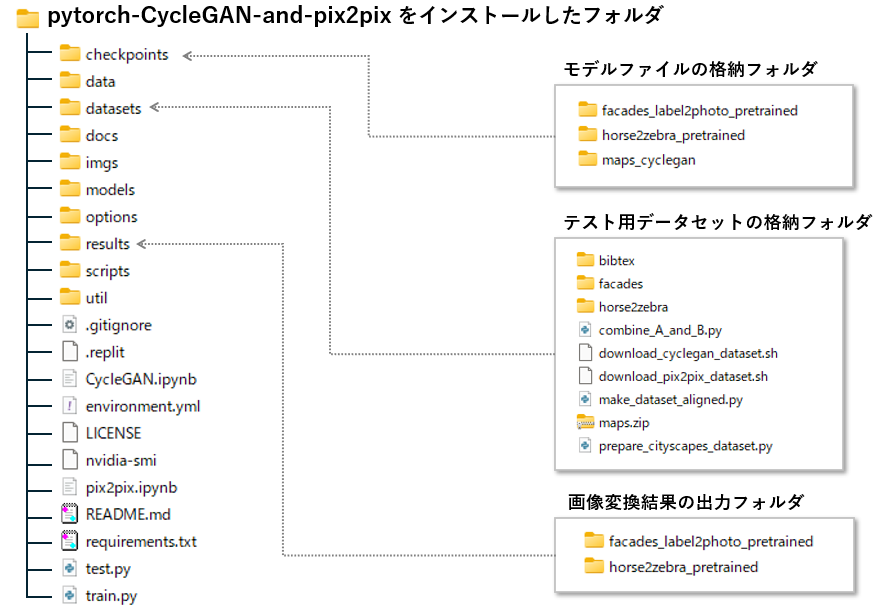
インストール後のフォルダ構成は上図の通りです。先ほどダウンロードしたモデルファイルは、checkpointsフォルダに、テスト用データセットは datasets フォルダに格納されています。
results は 現時点で存在しませんが、画像変換スクリプトを実行した時点で自動的に作成されます。
pytorch-CycleGAN-and-pix2pix の動作確認
コマンドプロンプトを開き、pytorch-CycleGAN-and-pix2pix をインストールしたフォルダに移動します。
cd pytorch-CycleGAN-and-pix2pix
pix2pix の動作確認
初めに、pix2pixの動作確認を行います。
下記のテストスクリプトを実行すると、results フォルダに結果(ビルの表面がそれっぽく描かれた画像)が出力されます。
python test.py --dataroot ./datasets/facades/ --direction BtoA --model pix2pix --name facades_label2photo_pretrained
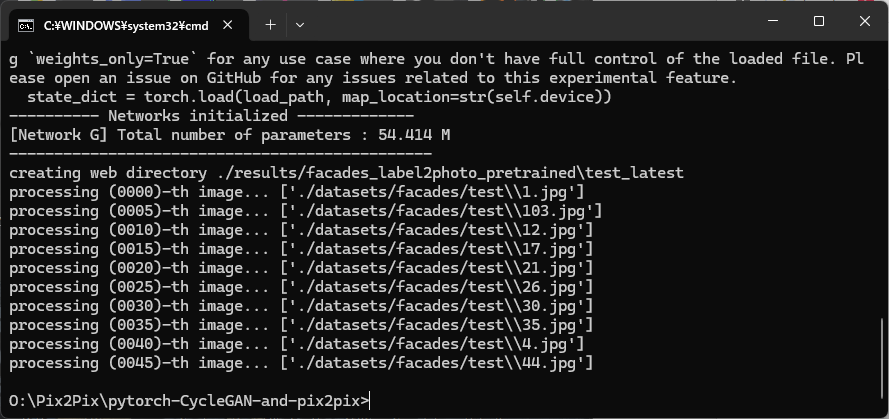
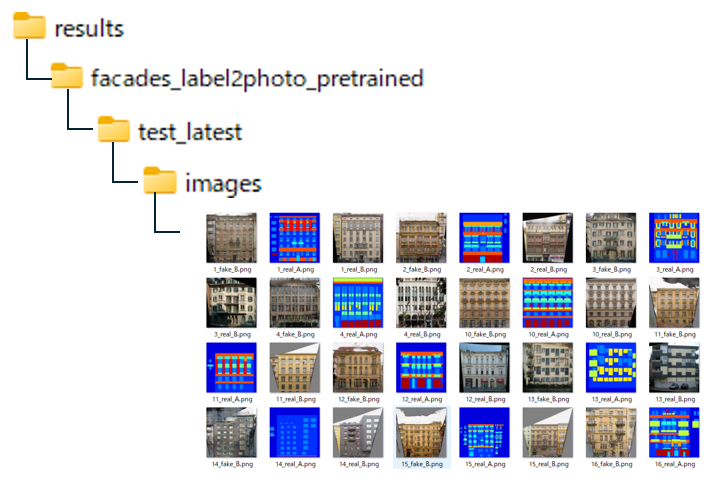
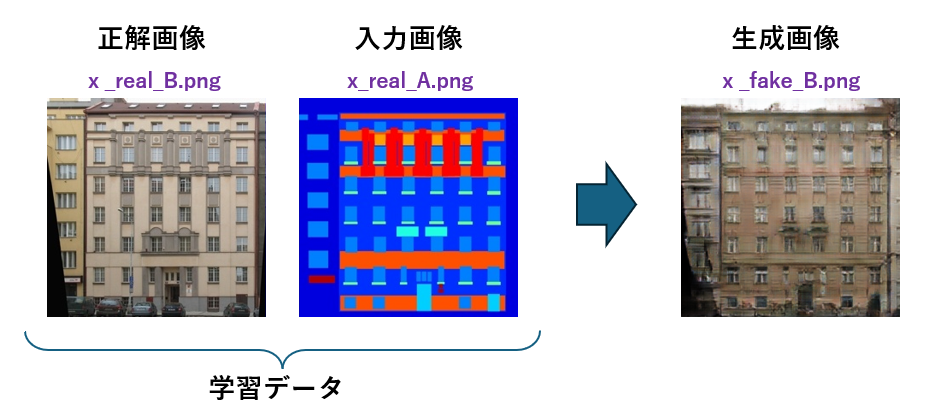
出力結果は、次の3つを1セットとして、106セット分が出力されています。
CycleGANの動作確認
次に、CycleGANの動作を確認します。
下記のテストスクリプトを実行すると、results フォルダに結果(普通の馬がシマウマの模様になる画像)が出力されます。
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout
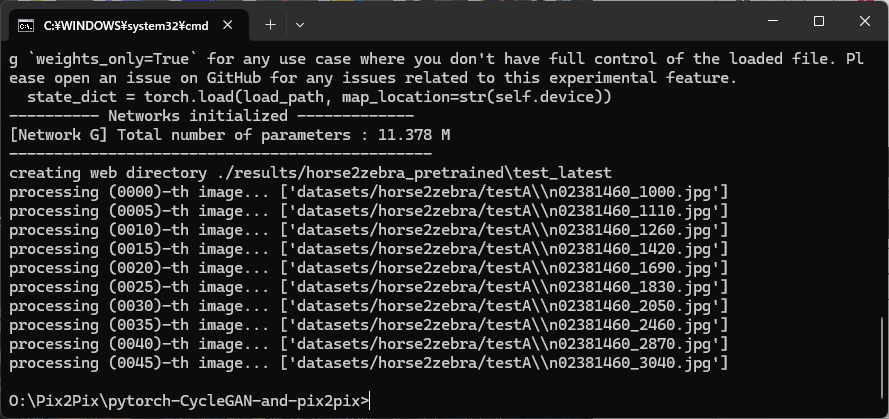

出力結果は、元の画像と変換後の画像を1セットとして、50セット分が出力されています。
学習のための準備
オリジナル画像

欠損画像(モザイク画像)

pix2pixモデルに学習させるためには、オリジナルと欠損画像(今回は口のモザイク)を用意する必要があります。
今回は Stable Diffusion を使って1000枚の画像を生成し、それを元にOpenCVを使って欠損画像を作成しました。
学習経過モニタリングツール(Visdom)の起動
Visdomと呼ばれるツールを使うことで、ブラウザ上でリアルタイムに学習の進捗状況を確認することができます。
次のコマンドの実行すると Visdomが起動します。このコマンドプロンプトは学習が終わるまで、このまま放置しておきます。
python -m visdom.server
初回起動時は下記の画面が表示されるので、「許可」をクリックします。

Visdomが起動すると、URL(黄色枠)が表示されます。

ブラウザのアドレス欄に http://localhost:8097/ を入力してエンターキーを押すと、Visdomが起動します。
pix2pix による学習
pix2pixは、対応するペア画像を用いて、入力画像の欠損部分を補完する生成モデルです。
そのため、今回のようなモザイク領域の復元タスクに対して非常に有効だと考えられます。
データセットの準備

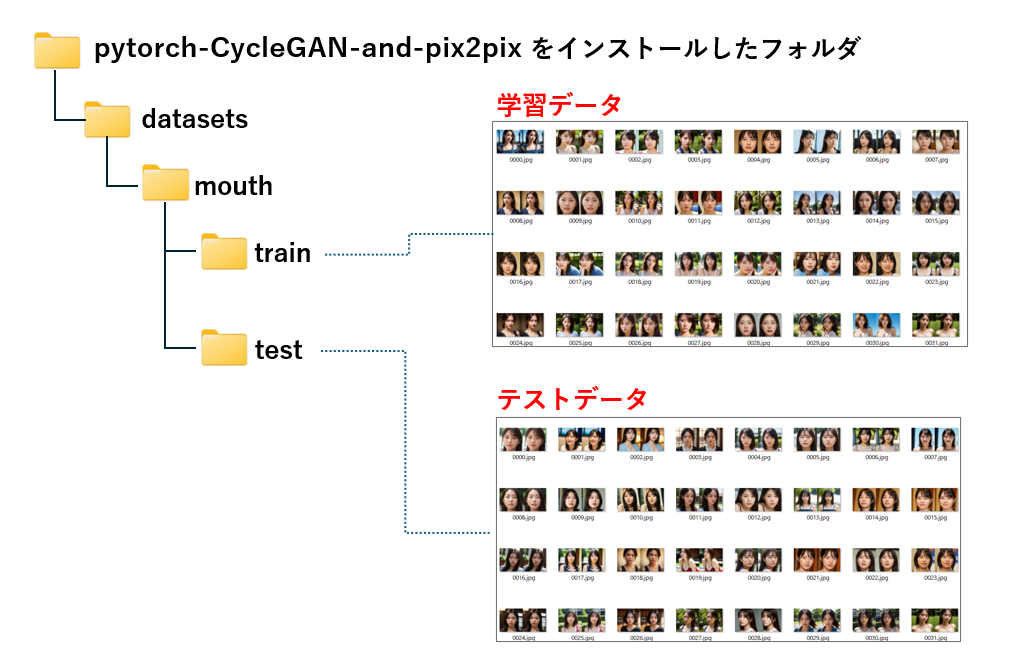
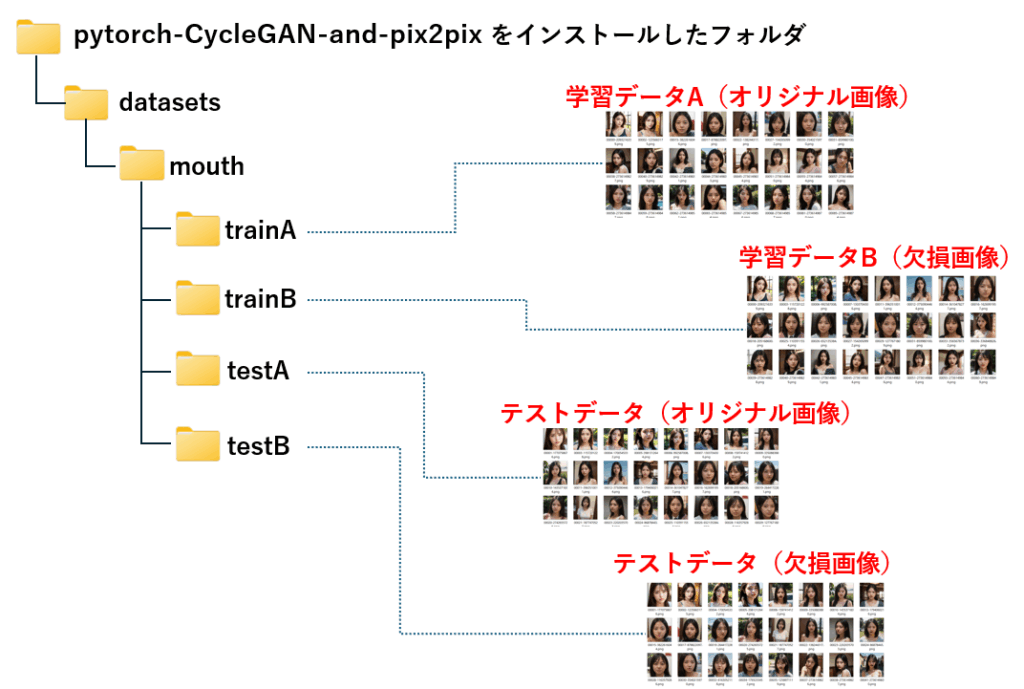
pix2pix でモデルを作成するには、オリジナルと欠損画像を左右に並べた画像を用意する必要があります。
元画像と欠損画像を左右に並べた画像を作成し、datasets フォルダ直下にサブフォルダ(今回はmouth)を作成、更にその下に train と test フォルダを作成し、学習画像(700枚)とテスト画像(300枚)を保存しました
学習の開始
pix2pix の学習には train.py を使います。
新しいコマンドプロンプトを開き、pytorch-CycleGAN-and-pix2pix をインストールしたフォルダに移動後、次のコマンドを実行してください。
python train.py --dataroot ./datasets/mouth --name mouth_pix2pix --model pix2pix --direction BtoA
train.py には次のオプションが指定できます。特に指定しなければ、epochが200で学習は終了します。epochを増やしたいときは --n_epochs を、前回の学習結果から続けたい場合は、--continue_train と --epoch_count を使うことで任意の epoch から再開できます。
| オプション名 | 説明 |
|---|---|
| --model | 使用するモデル(例: pix2pix, cycle_gan) |
| --dataset_mode | データセット形式(例: aligned, unaligned, single) |
| --direction | pix2pix用:AtoB or BtoA |
| --name | 実験名(チェックポイント保存ディレクトリ名になる) |
| --dataroot | データセットのパス |
| --n_epochs | 学習率一定の期間(例: 200) |
| --n_epochs_decay | 学習率を減衰させる期間(例: 100) |
| --epoch_count | 学習を開始するエポック番号(continue_trainと併用) |
| --load_size | 入力画像の読み込みサイズ(通常は256など) |
| --crop_size | クロップサイズ(通常は256) |
| --batch_size | バッチサイズ(例: 1や4) |
| --save_epoch_freq | 何エポックごとにモデルを保存するか(例: 5) |
| --print_freq | ログ出力の頻度(例: 100) |
| --display_freq | 可視化の頻度(例: 400) |
| --continue_train | 既存モデルの学習を再開 |
| --lr_policy | 学習率スケジューリング(例: linear, step, plateau) |
| --gpu_ids | 使用するGPU(例: 0, 0,1) |
| --num_threads | データ読み込みのスレッド数 |
| --save_by_iter | Trueであればiteration単位で保存 |
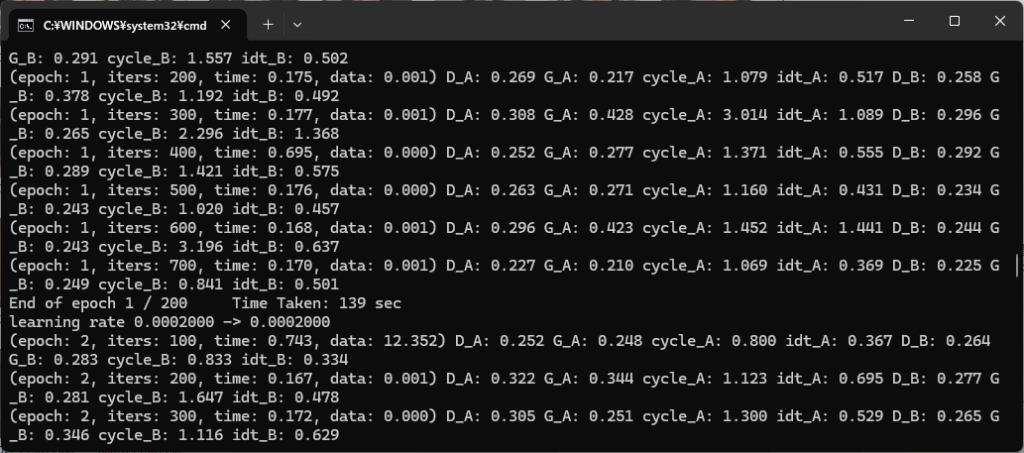
学習中は、コマンドプロンプトに以下の進捗状況が表示されます。

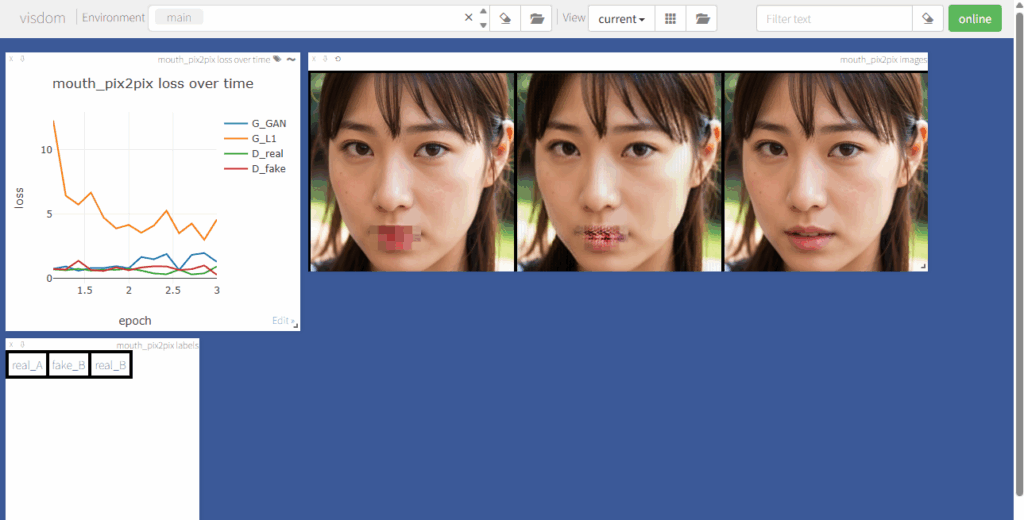
ブラウザで http://localhost:8097/ を表示すると、進捗状況が視覚的に確認できます。左のグラフは学習の進み具合を現わしていて、右側の3枚の写真は、それそれ「マスク画像」「現時点の補正結果」「元の画像」となっています。
学習は200 epoch で終了しますが、中央の写真が満足できる品質になった時点で、コマンドプロンプトにCtrl+C を入力し、強制終了させることも可能です。
学習済みモデルファイルは、checkpoints フォルダ配下の mouth_pix2pix フォルダに保存されています。
5 epoch ごとにモデルファイルが保存されており、latest_net_D.pth と latest_net_G.pth が最終結果です。
今回は 200 epoch で終了させましたが、その結果は次の通りです。Core-i5 13400 48GB + RTX-4070 で、約2時間かかりました。
中央の fake_B が補完結果です。200 epoch だとまだ物足りない印象ですが、それでもかなり補完されていますね。

pix2pixモデルの評価
次は、test フォルダの画像を、今回学習したモデルで補完してみましょう。コマンドプロンプトから次のコマンドを実行します。
python test.py --dataroot ./datasets/mouth --name mouth_pix2pix --model pix2pix --direction AtoB
テスト結果の画像は、下記のフォルダに出力されます。特に指定しなければ、45枚分の画像に対して補完が行われ、結果が images フォルダに出力されます。また、images の内容を一覧形式で確認するための index.html も自動生成されています。
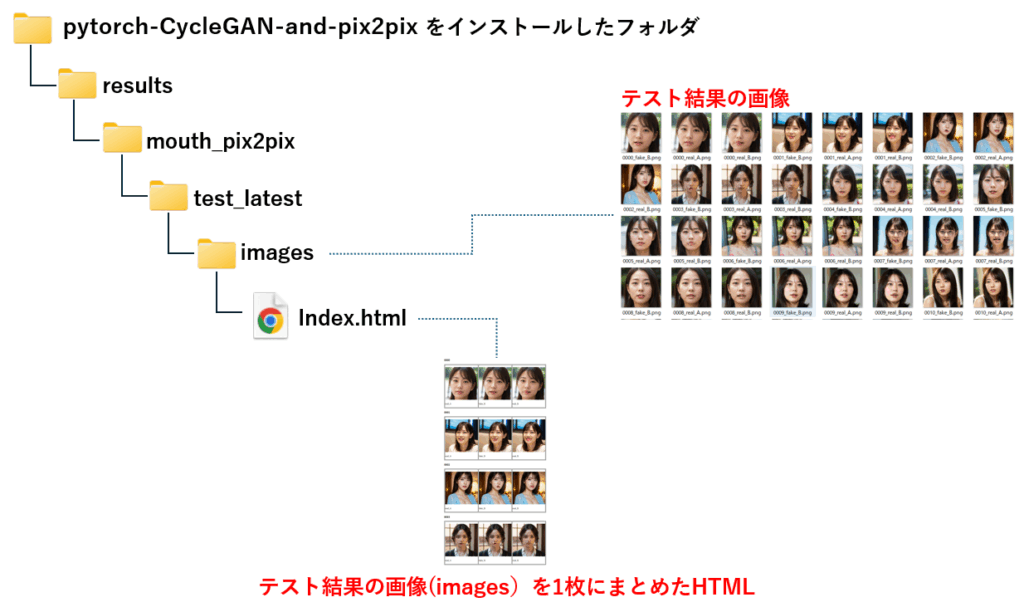
画像によって補完の程度は変わりますが、下記の画像(中央)では、かなり綺麗に補完されていることが分かります。

CycleGANによる学習
CycleGANは、画像Aと画像B間のスタイル変換を相互に学習するモデルです。そのため、通常の画像欠損領域の補完タスク――今回のようなモザイク除去――には直接的には適していないと考えられます
とはいえ、オリジナル画像とモザイク加工された画像のペアで学習させることで、「オリジナル画像 → モザイク画像」への変換モデルと、「モザイク画像 → オリジナル画像」への変換モデルの2つが構築されます。
このうち、「モザイク画像 → オリジナル画像」変換モデルを用いれば、モザイク領域の復元が出来そうです。
そこで、CycleGANにおいても、pix2pix と同じ画像を使ってモデルを構築することにします。
データセットの準備
CycleGANモデルに学習させるためには、オリジナルと欠損画像(今回は口のモザイク)を別々のフォルダに分けて格納する必要があります。具体的には、 trainA に学習用オリジナル画像、trainB に欠損画像、testAにテスト用オリジナル画像、testBにテスト用欠損画像を格納します。
学習の開始
CycleGANの学習は、pix2pixと同じく train.py を使います。
コマンドプロンプトから pytorch-CycleGAN-and-pix2pix をインストールしたフォルダに移動後、次のコマンドを実行してください。この時、--model に cycle_gan を指定するところがポイントです。
python train.py --dataroot ./datasets/mouth --name mouth_cyclegan --model cycle_gan
特に指定しなければ、epochが200で学習は終了します。epochを増やしたいときは --n_epochs を、前回の学習結果から続けたい場合は、--continue_train と --epoch_count を使用してください。
コマンドを実行すると、進捗状況が表示されます。
Visdom には、進捗状況として下記の内容が表示されます。
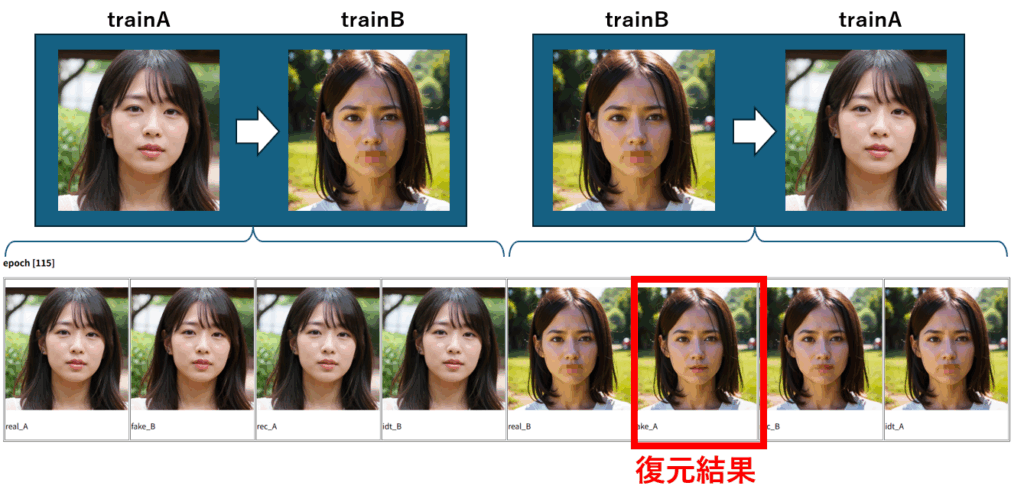
上段の画像は trainA ⇒ trainB に変換するモデルの学習状況、下段は trainB⇒trainA に変換するモデルの学習状況です。
trainAはオリジナル画像、trainB は欠損画像が格納されているため、このような表示になります。
尚、trainAとtrainBの画像ペアには対応関係がなく、評価時には両方のフォルダからランダムに画像が選択されるため、上下別々の画像になっています。
ここでは、下段の左から2番目に着目します。これは、欠損画像を復元した結果に相当します。

pix2pix の学習は、約2時間で200 epoch でしたが、CycleGANは学習に時間が掛かり、約2時間で 115 epoch しか進みませんでした。
学習済みモデルは、pix2pix と同様に checkpoints フォルダ直下の mouth_cyclegan フォルダに保存されています。
CycleGAN の評価
次は、test フォルダの画像を、今回学習したモデルで補完してみましょう。コマンドプロンプトから次のコマンドを実行します。
python test.py --dataroot ./datasets/mouth --name mouth_cyclegan --model cycle_gan
テスト結果の画像は、pix2pix と同様に resultsフォルダ直下の mouth_cyclegan フォルダに出力されます。
images の内容を一覧形式で確認するための index.html も自動生成されています。
下記はテスト結果の画像です。先頭から2種類の画像を抜粋しました。pix2pix と比べても負けないくらいの補完ができました。

データセット作成プログラム
下記は、pix2pix の学習用データセットを作成するためのサンプルプログラムです。src_folder_A にオリジナル画像、src_folder_B に欠損画像のフォルダを指定し、output_folder に出力先フォルダを指定するだけで、学習用とテスト用の(オリジナル画像と欠損画像を並べて1枚にしたもの)データセットが作成できます。
import os
import cv2
import random
def prepare_pix2pix_dataset(src_folder_A, src_folder_B, output_folder, train_ratio=0.7):
def concat_images(img1, img2=None):
if img2 is None:
return img1
if img1.shape[:2] != img2.shape[:2]:
img2 = cv2.resize(img2, (img1.shape[1], img1.shape[0]))
return cv2.hconcat([img1, img2])
files = [f for f in os.listdir(src_folder_A) if f.lower().endswith((".jpg", ".png", ".jpeg"))]
random.shuffle(files)
split_index = int(len(files) * train_ratio)
train_files = files[:split_index]
test_files = files[split_index:]
train_path = os.path.join(output_folder, "train")
test_path = os.path.join(output_folder, "test")
os.makedirs(train_path, exist_ok=True)
os.makedirs(test_path, exist_ok=True)
# TRAIN: A|B結合して保存
for i, fname in enumerate(train_files):
path_A = os.path.join(src_folder_A, fname)
path_B = os.path.join(src_folder_B, fname)
if not os.path.exists(path_B):
continue
img_A = cv2.imread(path_A)
img_B = cv2.imread(path_B)
pair = concat_images(img_A, img_B)
output_path = os.path.join(train_path, f"{i:04d}.jpg")
cv2.imwrite(output_path, pair)
# TEST: 同じく A|B結合して保存
for i, fname in enumerate(test_files):
path_A = os.path.join(src_folder_A, fname)
path_B = os.path.join(src_folder_B, fname)
if not os.path.exists(path_B):
continue
img_A = cv2.imread(path_A)
img_B = cv2.imread(path_B)
pair = concat_images(img_A, img_B)
output_path = os.path.join(test_path, f"{i:04d}.jpg")
cv2.imwrite(output_path, pair)
print(f"train: {len(train_files)}枚(A|B形式), test: {len(test_files)}枚(A|B形式)を保存しました。")
# 実行
prepare_pix2pix_dataset(
src_folder_A=r"P:\sample\original",
src_folder_B=r"P:\sample\mosaic",
output_folder=r"P:\sample\dataset",
train_ratio=0.7
)下記は、CycleGAN の学習用データセットを作成するためのサンプルプログラムです。src_folder_A にオリジナル画像、src_folder_B に欠損画像のフォルダを指定し、output_folder に出力先フォルダを指定するだけで、学習用とテスト用のデータセット(trainA,trainB,testA,testB)が作成できます。
import os
import shutil
import random
def prepare_cyclegan_dataset(src_folder_A, src_folder_B, output_folder, train_ratio=0.7):
def get_image_files(folder):
return [f for f in os.listdir(folder) if f.lower().endswith((".jpg", ".png", ".jpeg"))]
files_A = get_image_files(src_folder_A)
files_B = get_image_files(src_folder_B)
files_A = sorted(files_A) # Optional: sort for consistency
files_B = sorted(files_B)
random.shuffle(files_A)
random.shuffle(files_B)
split_A = int(len(files_A) * train_ratio)
split_B = int(len(files_B) * train_ratio)
trainA_files = files_A[:split_A]
testA_files = files_A[split_A:]
trainB_files = files_B[:split_B]
testB_files = files_B[split_B:]
def copy_files(file_list, src_folder, dst_folder):
os.makedirs(dst_folder, exist_ok=True)
for i, fname in enumerate(file_list):
src_path = os.path.join(src_folder, fname)
dst_path = os.path.join(dst_folder, fname)
shutil.copy2(src_path, dst_path)
# Copy trainA, testA, trainB, testB
copy_files(trainA_files, src_folder_A, os.path.join(output_folder, "trainA"))
copy_files(testA_files, src_folder_A, os.path.join(output_folder, "testA"))
copy_files(trainB_files, src_folder_B, os.path.join(output_folder, "trainB"))
copy_files(testB_files, src_folder_B, os.path.join(output_folder, "testB"))
print(f"trainA: {len(trainA_files)}枚, trainB: {len(trainB_files)}枚")
print(f"testA: {len(testA_files)}枚, testB: {len(testB_files)}枚")
# 実行例
prepare_cyclegan_dataset(
src_folder_A=r"P:\sample\original",
src_folder_B=r"P:\sample\mosaic",
output_folder=r"P:\sample\cyclegan_dataset",
train_ratio=0.7
)まとめ
今回は、画像の欠損補完(特に口元のモザイク除去)をテーマに、pix2pix(教師あり)とCycleGAN(教師なし)という2つの画像変換モデルを比較・検証しました。
一般的に pix2pix は、ペア画像(入力と正解)があるタスクに強く、線画の実写化や、欠損領域の補完といった 構造を忠実に再現したい場面に向いています。
一方、CycleGAN はペアが存在しないデータでも使えるため、馬 ↔ シマウマ、夏 ↔ 冬、写真 ↔ 絵画といった スタイルや質感の変換に適しています。
本来、今回のような欠損などの部分的な画像補完は、pix2pix のように対応画像ペアを使うモデルのほうが有利とされています。
しかし実際に試してみると、CycleGANでも思いのほか自然な補完が可能で、pix2pixと比べても大きく見劣りしない結果が得られました。
CycleGANはペアデータが用意できない場面での選択肢として、補完タスクでも一定の可能性を秘めていると言えるでしょう。







コメント