最近では Google Pixel や Photoshop のCMでも注目を集め、誰でも気軽に使えるようになってきました。
この記事では、そんな便利な画像補完処理を Python と LaMa モデルを使って “自分のPCで実行する方法” を徹底解説します。
環境構築から使用方法、実行結果の確認までを、手順を追ってわかりやすくご紹介していきます。
LaMaとは

LaMa(Large Mask Inpainting)は、画像の中で欠損や不要な領域をAIが自然に補完するための高度な技術です。特に「構造が複雑」「背景との馴染みが重要」といった条件でも、極めてリアルな仕上がりを得られることで注目されています。
LaMaの特徴とポイント
- 周囲情報からの推論で自然に復元
テクスチャ・構造を理解して描き直すため、背景に溶け込むような結果が得られます。 - 従来手法よりも広域対応が可能
U-NetやPartial Convolutionを超えて、大きな欠損領域にも強い補完力を発揮。 - 効率的なモデル構造(FFC)を採用
Fast Fourier Convolutionにより、局所情報とグローバル構造の両方を捉えるアプローチが実装されています。 - 公式実装はPyTorchベースで公開中
GitHubで誰でも無料で利用でき、学習済みモデルも提供されているため、環境構築すればすぐに試せます。
LaMa の公式サイト
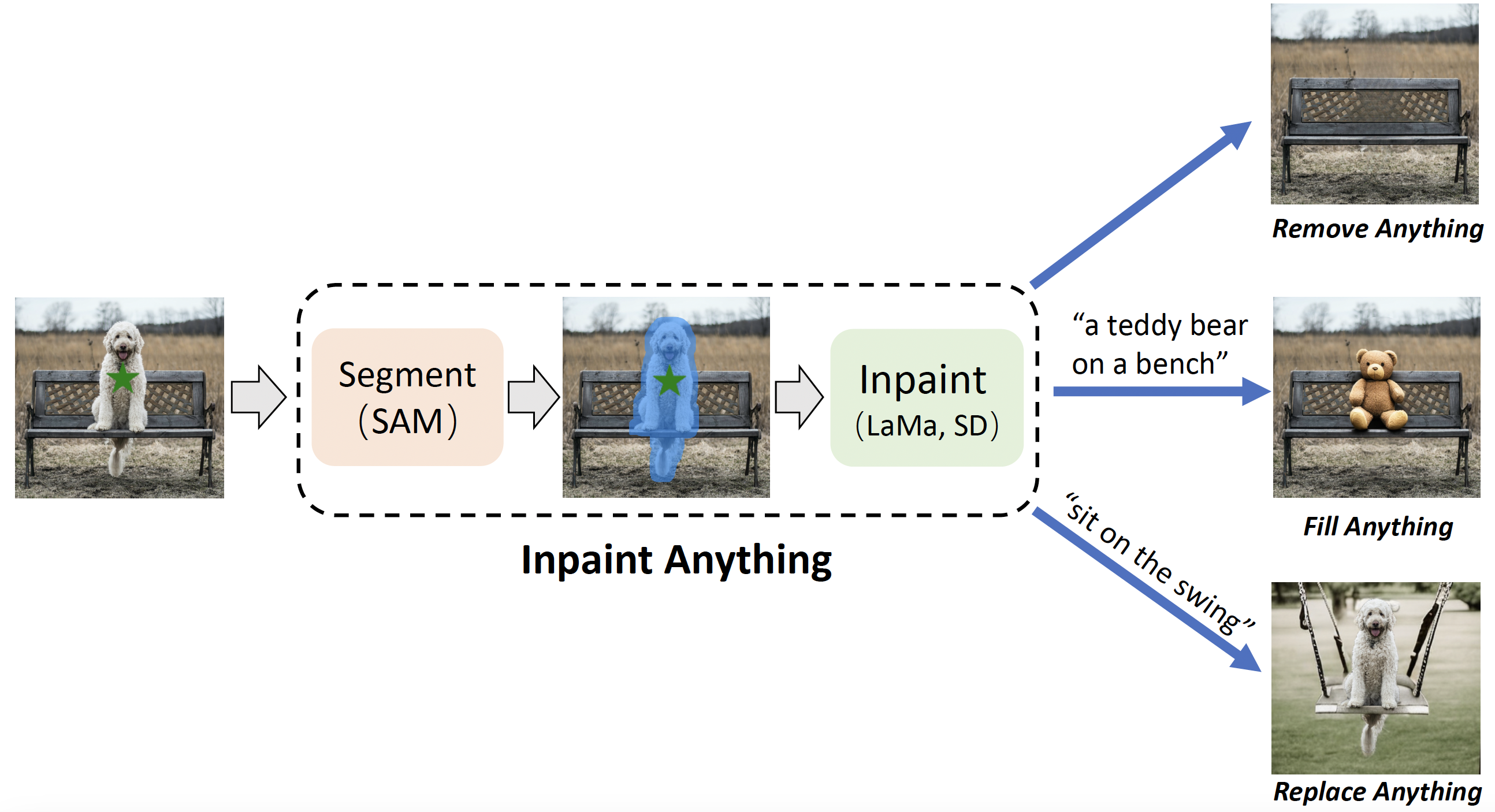
LaMa の概要とソースコード、インストール方法は、GitHubの LaMa 公式ページに掲載されています。
本記事では、ここに記載されいている内容をできるだけわかりやすく解説したものになります。
https://github.com/advimman/lama
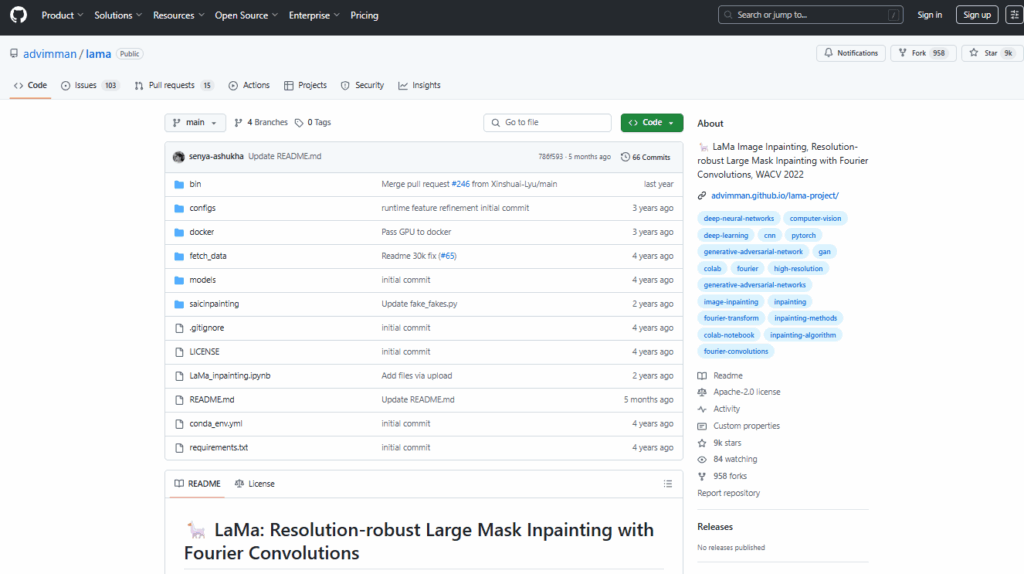
インストールの前提条件
DeblurGANのページでは、モデルのダウンロード方法とデモプログラムの使い方に関する記述があるだけで、詳しいインストール方法が記載されていません。
今回は、私のPCで試して動作した構成を記載しています。
Python/CUDAのバージョン
動作に必要な環境は次の通りです。
| 必要な環境・ライブラリ | バージョンなど | 備考 |
|---|---|---|
| Python 環境 | Python 3.8.10 | |
| Git 環境 | その時の最新版 | |
| Pytorch | torch 1.8.0+cu111 | |
| CUDA Toolkit | 11.1 | |
| cuDNN | 8.0.5 |
インストール手順の概要
次の手順でインストールを行います。
| Step1 Python動作環境の構築 | ①Python 3.8.10の環境準備 ②Gitの環境準備 ③CUDA Toolkit 111のインストール ④cuDNN 8.0.5 |
|---|---|
| Step2 LaMa のインストール | GitHubからLaMa をインストール後、各種モジュールをインストール |
| Step3 各種モデルのインストール | GitHubに公開されている学習済みモデルをダウンロードします。 これは、コマンドを1行実行することで完了します。 |
インストール手順
Step1.Python動作環境の構築
「【最初の一歩】生成AI向けPython環境構築手順(スクリーンショットで解説)」の記載内容(①②③④)を実行してください。
Python環境構築手順の①~④をインストールしてください。
FFMPEGのインストールは不要です(使わないだけなので、インストールしても差し支えはありません)。
Step2.LaMa のインストール
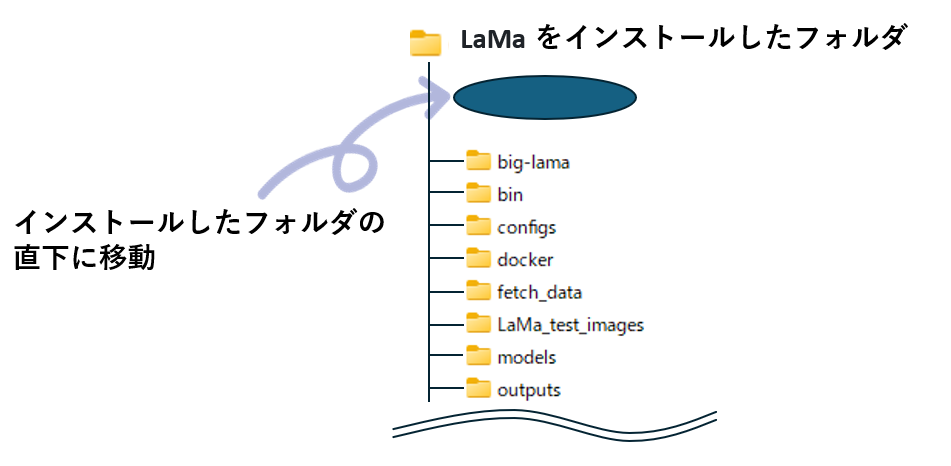
あらかじめ、LaMa をインストールするための任意のフォルダを作成しておきます。今回は、Oドライブの直下に LaMaというフォルダを作成し、そこにインストールすることにします。
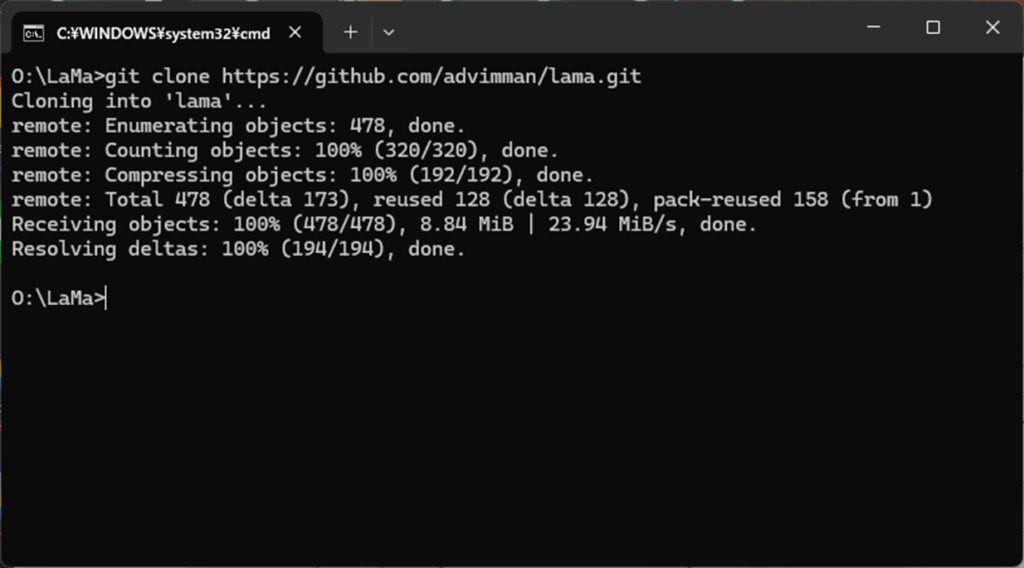
まず、コマンドプロンプトを開き、インストールしたいフォルダ(今回はOドライブ直下の LaMaフォルダ)に移動し、次のコマンドを実行します。
git clone https://github.com/advimman/lama.git
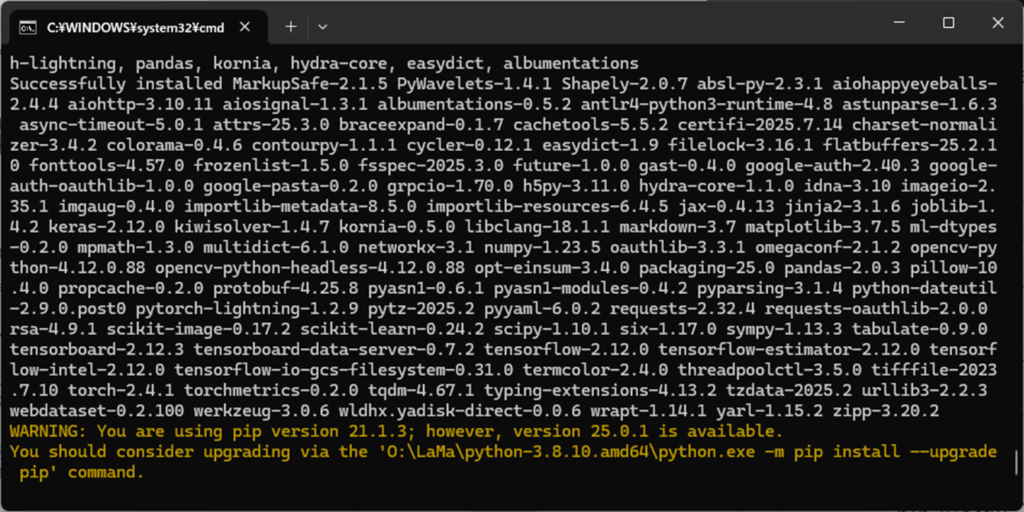
LaMa のモジュールのインストールに成功したら、次のコマンドを実行してください。
cd lama
pip install -r requirements.txt
次に、pytorch と TorchVision をインストールします。こちらは、CPU版とGPU版の2種類が用意されているので、お使いの環境によって使い分けて下さい。
CPU対応版でLaMaを使う場合
pip install torch==1.8.0 torchvision==0.9.0
GPU対応版でLaMaを使う場合
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
Step3.学習済みモデルのインストール
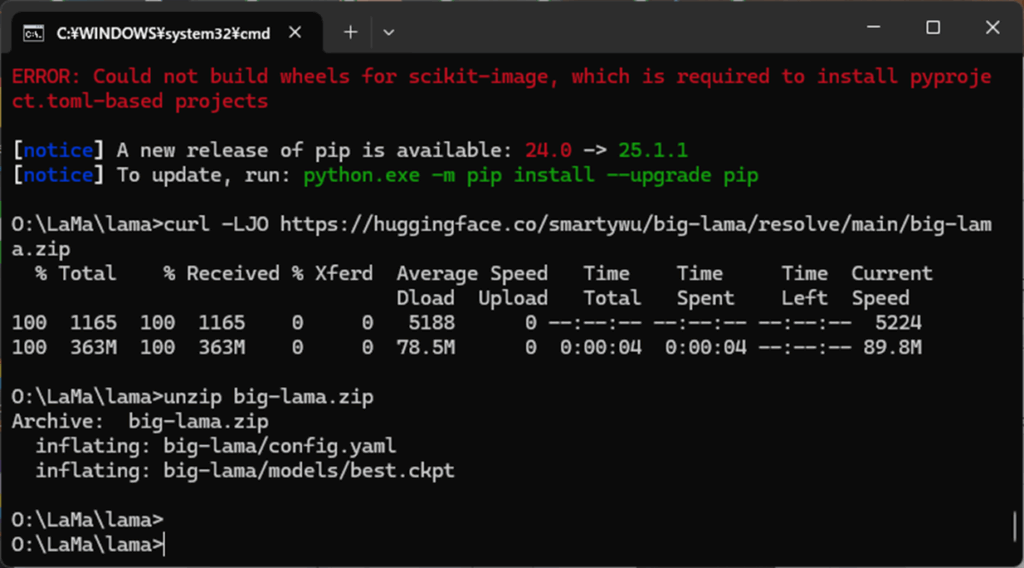
学習済みモデルは、次のコマンドでインストール可能です。これにより、モデルファイルが自動的にダウンロードされ、big-lamaフォルダに展開されます。
curl -LJO https://huggingface.co/smartywu/big-lama/resolve/main/big-lama.zip
unzip big-lama.zip
LaMa のフォルダ構成について
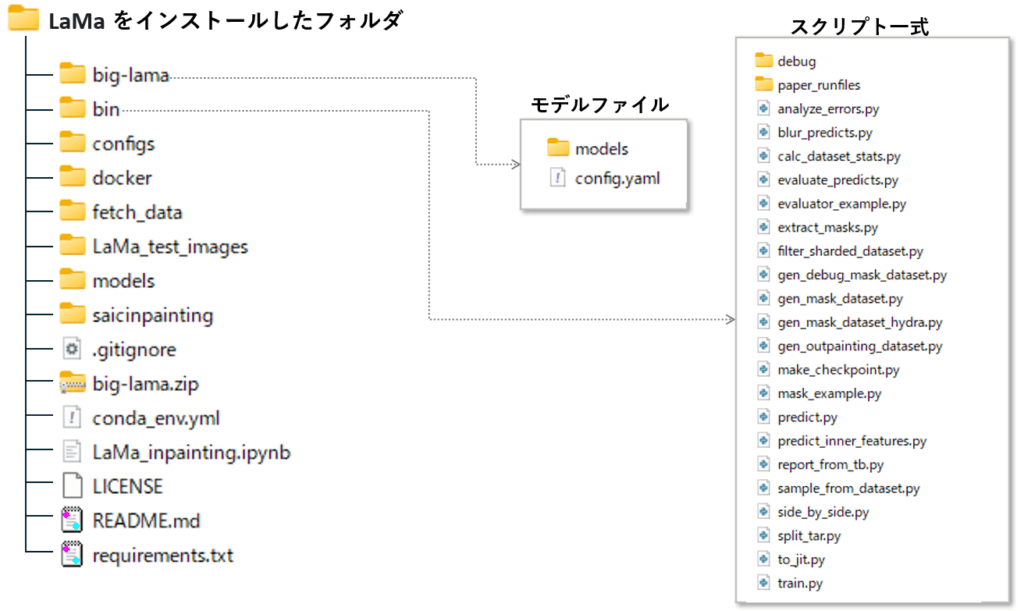
ここまでの手順が完了すると、上記のフォルダ構成になっています。
bin フォルダにスクリプトが格納されていますので、参考までに概要を纏めておきました。
画像から不要部分を消すには、predict.py を使います。
| ファイル名 | 目的・役割 |
|---|---|
| analyze_errors.py | 予測ミスやエラーの傾向を調べる分析ツール |
| blur_predicts.py | 予測画像にぼかし処理を加える補正用スクリプト |
| calc_dataset_stats.py | データセット全体の統計情報を集計(画素分布など) |
| evaluate_predicts.py | 推論結果の精度を定量的に評価する |
| evaluator_example.py | 評価スクリプトの使用例を示すサンプル |
| extract_masks.py | 入力画像や予測結果からマスク領域を抽出 |
| filter_sharded_dataset.py | 分割保存されたデータから必要なサンプルだけ抽出 |
| gen_debug_mask_dataset.py | デバッグ用の特殊なマスク付きデータを作成 |
| gen_mask_dataset.py | 学習や推論用のマスク付きデータセットを生成 |
| gen_mask_dataset_hydra.py | 設定ファイルベースで柔軟にマスクを生成する |
| gen_outpainting_dataset.py | 外側を補完する画像生成用データセットを作成 |
| make_checkpoint.py | モデルの学習状態を保存(チェックポイント) |
| mask_example.py | マスク生成処理の使用例・挙動確認に使う |
| predict.py | 学習済みモデルを使って推論処理を実行する本体 |
| predict_inner_features.py | モデル内部の特徴量(中間層)を抽出する |
| report_from_tb.py | TensorBoard のログから学習レポートを作成 |
| sample_from_dataset.py | データセットから一部を抜き出してサンプル化 |
| side_by_side.py | 入力画像・予測画像などを横並びで可視化 |
| split_tar.py | 大容量の tar ファイルを分割して扱いやすくする |
| to_jit.py | モデルを JIT 形式に変換して高速化・移植性向上 |
| train.py | モデルの学習処理を実行するメインスクリプト |
画像の準備
LaMaに不要な部分を指定するためには、マスク画像を用意する必要があります。マスク画像は背景が黒で、削除したい範囲を白で塗りつぶします。
この時、ファイル名は元のファイル名の末尾に "_mask" を付加する必要があります。また、画像は png 形式で保存しておきます。
テスト画像として下記の画像を用意しました。あらかじめ、右クリックでダウンロードしてください。
元画像(pngample1.png)

マスク画像(pngample1_mask.png)

元画像(sample2.png)

マスク画像(sample2_mask.png)

元画像(sample3.png)

マスク画像(sample3_mask.png)

マスク画像作成スクリプト
削除したい部分を黒く塗りつぶした画像から、マスク画像を作る関数を用意しました。ご自身の画像で試してみたい場合は、これでマスク画像を作ると便利です。
元画像から削除部分を黒く塗りつぶす

左の画像からマスク画像を作成

import cv2
import numpy as np
import os
def process_black_mask(folder_path, output_path=None):
"""
指定フォルダ内の画像から、真っ黒なピクセル(RGB: 0,0,0)を検出し、
白黒マスク画像を生成して保存します。
Args:
folder_path (str): 入力画像が保存されているフォルダの絶対パス。
output_path (str, optional): 生成されたマスク画像の保存先フォルダ。
指定しない場合は `folder_path + "_masked"` が使われます。
Returns:
None: 画像ごとのマスクファイルが保存され、関数自体の返り値はありません。
Note:
マスク画像では黒ピクセルが白(255)、その他の領域が黒(0)になります。
元画像と同じファイル名・拡張子で保存されます。
"""
os.makedirs(output_path or folder_path + "_masked", exist_ok=True)
for fname in os.listdir(folder_path):
if fname.lower().endswith(('.png', '.jpg', '.jpeg')):
img_path = os.path.join(folder_path, fname)
img = cv2.imread(img_path)
# 真っ黒なピクセルを検出(RGB全部が0)
black_pixels = np.all(img == [0, 0, 0], axis=-1)
# 白黒マスク作成:黒→白、それ以外→黒
mask = np.where(black_pixels, 255, 0).astype(np.uint8)
# 保存(拡張子は元と同じ)
save_path = os.path.join(output_path or folder_path + "_masked", fname)
cv2.imwrite(save_path, mask)
print(f"Processed: {fname}")
## -- 使い方のサンプル ----
process_black_mask(r"O:\LaMa\lama\LaMa_test_images", r"O:\LaMa\lama\LaMa_test_images\mask")元の画像とマスク画像を重ね合わせて表示する関数も作りましたので、もしよければお使いください。
元画像

マスク画像

元画像とマスク画像の重ね合わせ

def overlay_with_partial_transparency(folder_path, output_path=None, mask_suffix='_mask', transparency_for_white=0.7):
"""
指定フォルダ内の RGB 画像と対応する白黒マスク画像を元に、
マスク領域を部分的に透過した RGBA 画像を作成・保存します。
Args:
folder_path (str): 入力元の画像・マスクが保存されたフォルダのパス。
output_path (str, optional): 出力先フォルダ。未指定の場合は `folder_path + "_overlay_alpha"` に保存。
mask_suffix (str, optional): マスク画像のファイル名に付くサフィックス。デフォルトは '_mask'。
transparency_for_white (float, optional): 白ピクセル(255)の透過率(0~1.0)。例: 0.7で70%透明。
Returns:
None: RGBA画像ファイルが保存され、標準出力に処理ログを表示。関数自体の返り値はなし。
Note:
- 入力画像とマスク画像はファイル名ベースでペアになります(例: sample.png と sample_mask.png)。
- マスク領域(白)を指定透過率にし、それ以外は完全不透明で出力されます。
- 出力画像形式は `.png` 固定(αチャンネルを含むため)。
"""
os.makedirs(output_path or folder_path + "_overlay_alpha", exist_ok=True)
for fname in os.listdir(folder_path):
if fname.lower().endswith(('.png', '.jpg', '.jpeg')) and mask_suffix not in fname:
base_name, ext = os.path.splitext(fname)
img_path = os.path.join(folder_path, fname)
mask_path = os.path.join(folder_path, base_name + mask_suffix + '.png')
if not os.path.exists(mask_path):
print(f"⚠️ Mask not found for {fname}, skipping.")
continue
# 読み込み
img = cv2.imread(img_path)
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
# アルファチャンネル作成(255が白、白を部分透明にする)
alpha = np.full_like(mask, 255, dtype=np.uint8)
alpha[mask == 255] = int(transparency_for_white * 255)
# RGBA画像作成(RGBそのまま、αのみ反映)
rgba = cv2.merge([img[:, :, 0], img[:, :, 1], img[:, :, 2], alpha])
# 保存
out_name = base_name + '_overlay_alpha.png'
out_dir = output_path or folder_path + "_overlay_alpha"
cv2.imwrite(os.path.join(out_dir, out_name), rgba)
print(f"✅ Saved: {out_name}")
## -- 使い方のサンプル ----
overlay_with_partial_transparency(
folder_path=r"O:\LaMa\lama\LaMa_test_images",
output_path=r"O:\LaMa\lama\LaMa_test_images\mask",
transparency_for_white=0.2
)predict.pyの使い方
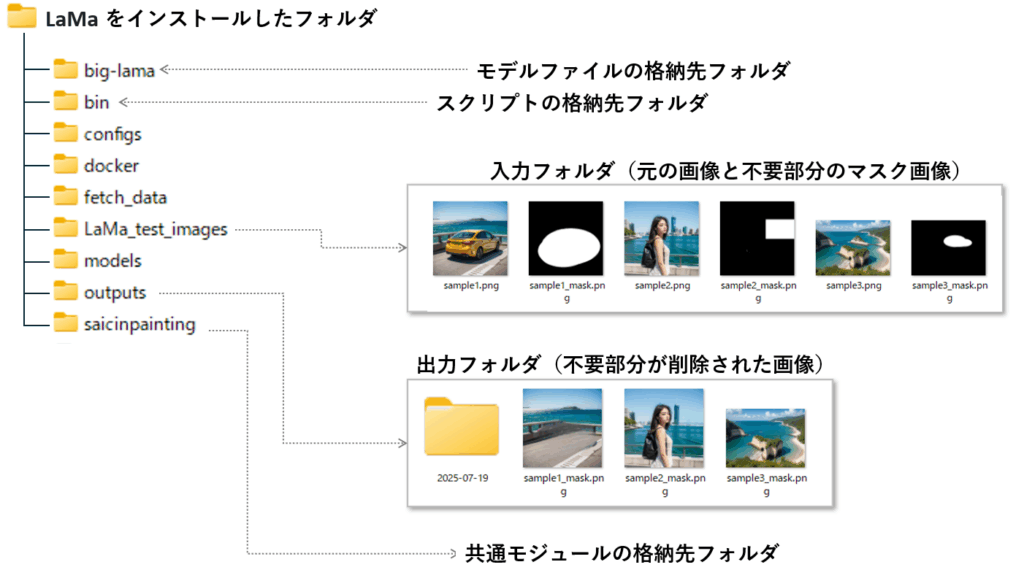
デモのスクリプトを動かす前に、テスト画像を所定のフォルダにコピーする必要があります。
今回は、LaMa_test_images という名前でフォルダを作って、そこに処理したい画像を入れることにします。
結果の出力先フォルダ(今回の例では outputs フォルダ)は、スクリプト実行時に自動作成されます。
不要部分を消去するには、predict.py に次のパラメータを指定します。
python bin/predict.py model.path=モデルフォルダのパス indir=入力フォルダのパス outidr=出力フォルダのパス
この時、パラメータに指定するパスは絶対パスで指定します。相対パスだと、指定した場所を正しく見つけてくれません。
また、スクリプト実行時は、PYTHONPATH という環境変数に、LaMaのインストールフォルダを設定する必要があります。これは、saicinpainting フォルダに格納された共通モジュールを参照する必要があるためです。
SET PYTHONPATH=LaMaのインストールフォルダ/lama
下以下は、PYTHONPATH 環境変数の値を使って、predict.py を実行する具体例です。
SET PYTHONPATH="o:\LaMa\lama"
Python %PYTHONPATH%\bin\predict.py model.path=%PYTHONPATH%\big-lama indir=%PYTHONPATH%\LaMa_test_images outdir=%PYTHONPATH%\lama\output
predict.py の 44行目を修正(GPUを使う場合のみ必要)
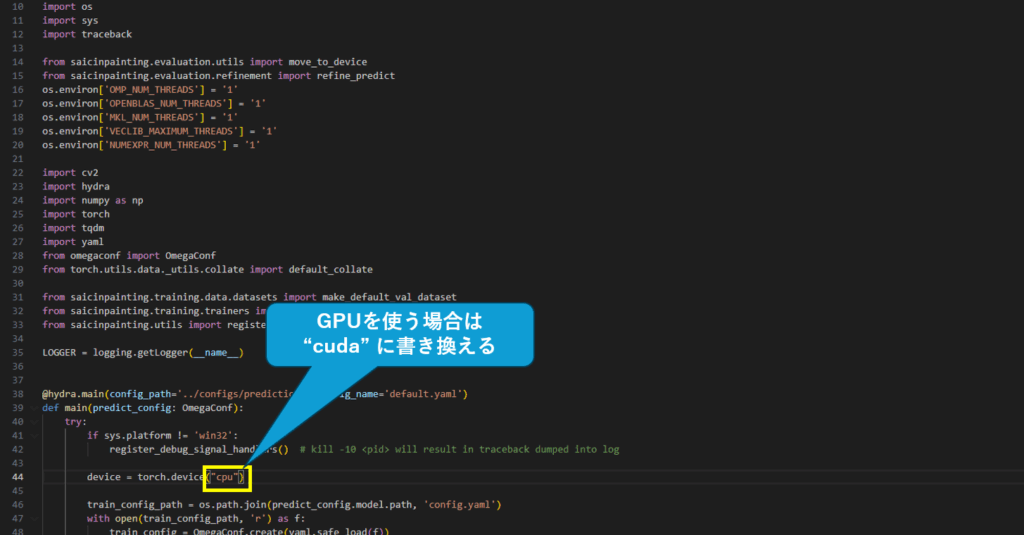
GPU対応版のインストールを行ったとしても、predict.pyの44行目を cuda に書き換えないとGPUを使ってくれませんのでご注意ください。
device = torch.device("cuda")不要部分の消去(predict.pyの実行)
コマンドプロンプトから、LaMaをインストールしたフォルダに移動し、PYTHONPATH 環境変数を設定した後で、predict.pyを呼び出します。
実際に試される場合は、ドライブやフォルダ名を、ご自身の環境と置き換えてください。
LaMaのインストールフォルダ⇒o:\LaMa\lama
入力フォルダ⇒o:\LaMa\lama\LaMa_test_images
出力フォルダ⇒o:\LaMa\lama\outputs
SET PYTHONPATH="o:\LaMa\lama"
Python %PYTHONPATH%\bin\predict.py model.path=%PYTHONPATH%\big-lama indir=%PYTHONPATH%\LaMa_test_images outdir=%PYTHONPATH%\lama\output
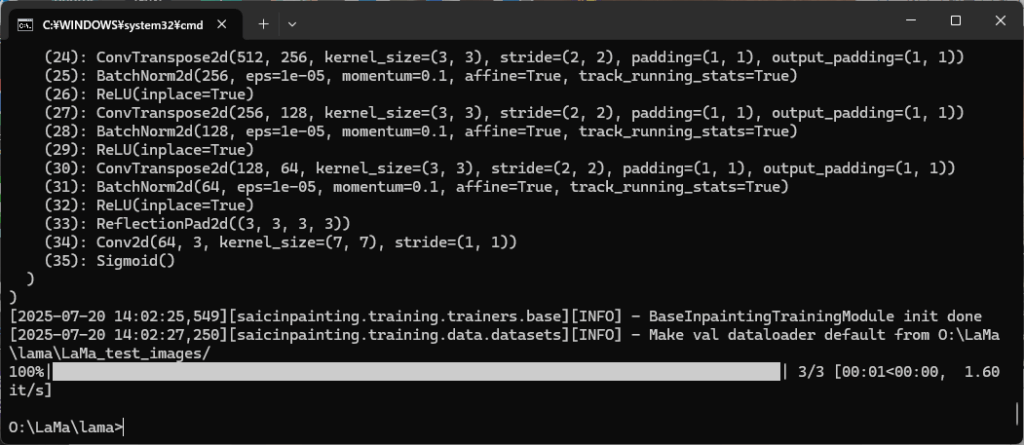
実行結果
実行すると数秒~十数秒後(GPUの性能により異なる)で出力フォルダ(今回はoutputs)に指定部分が消えた画像が出力されます。
1枚目(sample1.png)はさすがに消去する面積が大きいため、それなりに不自然な消え方になりました。
元画像+マスク画像(白い楕円が削除対象)

出力結果(不要部分が消去された画像)

2枚目(sample2.png)の背の高いビルは、完全にマスク領域に覆われていなかったためか、丸ごと残ってしまいましたが、マスク領域に収まっていた部分は、完全に消去されました。
元画像+マスク画像(白い四角形が削除対象)

出力結果(不要部分が消去された画像)

3枚目(sample3.png)は元画像を知っていれば、少し違和感があるかもしれませんが、出力結果だけしか見ていなければ、そこに島があったことが気づけないくらい綺麗に消えました。
元画像+マスク画像(白い楕円が削除対象)

出力結果(不要部分が消去された画像)

まとめ
本記事では、LaMaというAI画像補完ツールの使い方や導入手順を、キャプチャ画像を使って分かり易くまとめました。
背景と自然に馴染むような補完ができるのがLaMaの特徴で、従来のツールよりもリアルな仕上がりが得られます。
Python環境さえあればすぐに試せるので、画像編集に興味がある方はぜひ挑戦してみてください。







コメント